

Сегодня расскажем, как осуществляется мониторинг использования ресурсов Linux и использование ограничений процесса для каждого пользователя — LFCS часть 14. Каждый системный администратор Linux должен знать, как проверить целостность и доступность оборудования, ресурсов и ключевых процессов. Кроме того, установка ограничений ресурсов для каждого пользователя также является обязательной частью набора навыков.
В этой статье мы рассмотрим несколько способов обеспечения правильной работы системы. Мы имеем ввиду как аппаратное, так и программное обеспечение, чтобы избежать возможных проблем, которые могут привести к неожиданному простою производства и денежным потерям.
Статистика процессоров Linux
С помощью mpstat вы можете просматривать информацию о каждом процессоре по отдельности или о системе в целом, как в виде одноразового моментального снимка, так и динамически.
Чтобы использовать этот инструмент, вам необходимо установить sysstat:
После того, как вы установили mpstat, используйте его для создания отчетов по статистике процессоров.
Чтобы отобразить 3 глобальных отчета об использовании ЦП (-u) для всех ЦП (как указано -P ALL) с интервалом в 2 секунды, выполните:

Образец вывода:
Чтобы просмотреть ту же статистику для конкретного ЦП (CPU 0 в следующем примере), используйте:
Образец вывода:
Разберём подробнее вывод выше приведенных команд по столбцам:
- CPU: номер процессора.
- % usr: процент использования процессора во время работы приложений уровня пользователя.
- % nice: то же, что и % usr, но с большим приоритетом.
- % sys: процент загрузки процессора, который происходит при выполнении приложений ядра. Этот параметр не включает время, затрачиваемое на прерывания или обработку аппаратного обеспечения.
- % iowait: процент времени, когда данный CPU (или все) был бездействующим, в течение которого была запланирована ресурсоемкая операция ввода-вывода на этом CPU. Более подробное объяснение (с примерами) можно найти здесь.
- % irq: процент времени, затрачиваемого на обслуживание аппаратных прерываний.
- % soft: то же, что и % irq, но с программными прерываниями.
- % steal: процент времени, проведенного в непроизвольном ожидании, когда виртуальная машина, как гостевая, «забирает» внимание гипервизора, конкурируя за процессор(ы). Это значение должно быть как можно меньше. Высокое значение в этом поле означает, что виртуальная машина задерживает работу системы.
- % guest: процент времени, затрачиваемого на запуск виртуального процессора.
- % idle: процент времени, когда CPU не выполняли никаких задач. Если вы наблюдаете низкое значение в этом столбце, это указывает на то, что система находится под большой нагрузкой. В этом случае вам нужно будет более внимательно изучить список процессов (как это сделать мы обсудим через минуту), чтобы определить, чем это вызвано.
Чтобы максимально нагрузить процессор, выполните следующие команды, а затем выполните mpstat (как показано ниже) в отдельном терминале:

Наконец, сравните с выводом mpstat при «нормальных» обстоятельствах:
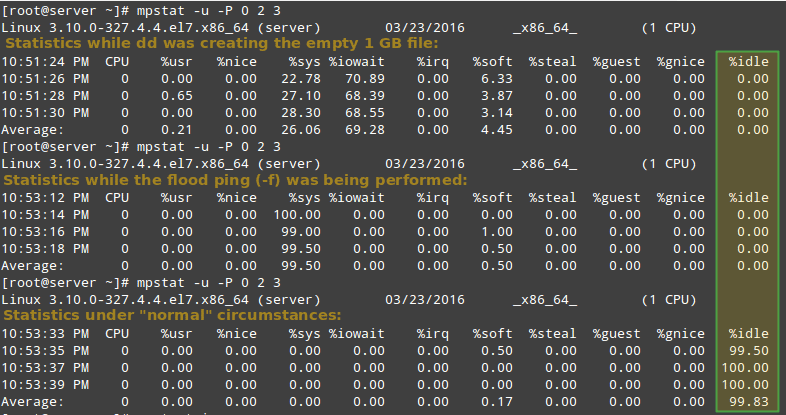
Как видно на скриншоте выше, CPU 0 находился под большой нагрузкой во время первых двух примеров, это указано в столбце % idle.
В следующем разделе мы обсудим, как идентифицировать эти ресурсоемкие процессы, как получить больше информации о них и как предпринять соответствующие действия.
Отчеты о процессах Linux
Чтобы просмотреть процессы, отсортированные по использованию ЦП, мы будем использовать известную вам команду ps с параметром -eo (для выбора всех процессов пользовательского формата) и -sort (для указания порядка пользовательской сортировки), например:
Вышеприведенная команда будет показывать только PID, PPID, команду связанную с процессом, и процент использования процессора и ОЗУ, отсортированные по проценту использования ЦП в порядке убывания. , Вот первые несколько строк вывода, во время создания файла .iso:
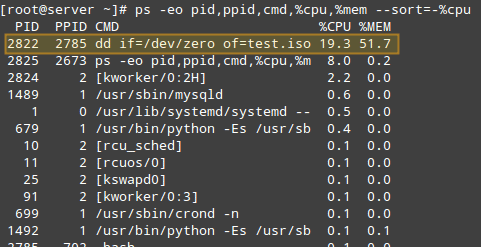
Как только мы определили интересующий вас процесс (например, с PID = 2822), в этом случае мы можем перейти к /proc/PID (/proc/2822) и вывести список каталогов.
Этот каталог содержит несколько файлов и подкаталогов с подробной информацией об этом конкретном процессе, которые сохраняются во время работы.
Например:
- /proc/2822/io содержит статистику IO для процесса (количество символов и байтов, считанных и записанных, в частности, во время операций ввода-вывода).
- /proc/2822/attr/current отображает текущие атрибуты безопасности SELinux для процесса.
- /proc/2822/cgroup описывает управляющие группы, к которым принадлежит процесс, если включена опция конфигурации ядра CONFIG_CGROUPS, которую вы можете проверить с помощью:
Если опция включена, вы должны увидеть:
Используя группы, вы можете управлять объемом разрешенного использования ресурсов на основе каждого процесса, как описано в главах с 1 по 4 руководства по управлению ресурсами Red Hat Enterprise Linux 7, а также в главе 9 руководства по системному анализу и настройке openSUSE.
/proc/2822/fd — это каталог, который содержит одну символическую ссылку для каждого дескриптора файла, который открыл процесс. На следующем скриншоте показана эта информация для ограничения процесса, который был запущен в tty1 (первый терминал), чтобы создать образ .iso:
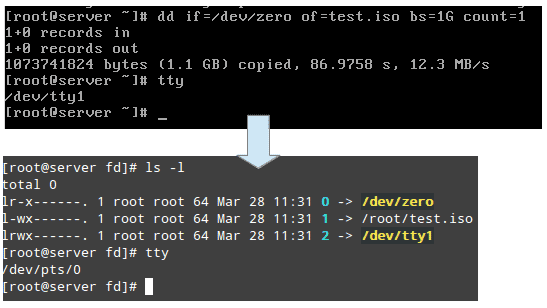
На приведенном выше скриншоте показано, что stdin (файловый дескриптор 0), stdout (дескриптор файла 1) и stderr (дескриптор файла 2) отображаются соответственно /dev/zero, /root/test.iso и /dev/tty1.
Более подробную информацию о /proc можно найти в документе «Документация файловой системы /proc», хранящемся и поддерживаемом Kernel.org, а также в Руководстве программиста Linux.
Установка лимитов ресурсов для пользователей в Linux
Если вы не будете не осторожны и разрешите любому пользователю запускать неограниченное количество процессов, вы можете столкнуться с неожиданным отключением системы или её блокировкой, поскольку система переходит в перегруженное состояние. Чтобы этого не произошло, вы должны установить ограничение на количество процессов, которые пользователи могут запускать.
Для этого отредактируйте файл /etc/security/limits.conf и добавьте следующую строку в нижней части файла, чтобы установить ограничение:
Первое поле может использоваться для обозначения пользователя или группы (*), тогда как второе поле принудительно устанавливает ограничение на количество процессов (nproc) до 10. Чтобы применить изменения, выйдите из системы и зайдите обратно, этого будет достаточно.
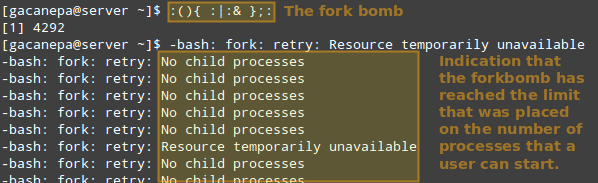
Таким образом, давайте посмотрим, что произойдет, если какой-либо пользователь, не root, попытается запустить fork-бомбу (вредоносная или ошибочно написанная программа, создающая цыкл). Если бы мы не применили ограничения, сначала это запустило бы два экземпляра функции, а затем дублировало бы каждый из них в бесконечном цикле. Таким образом, это в конечном итоге привело бы вашу систему к выходу из строя.
Однако, с указанным выше ограничением, fork-бомба не страшна, но пользователь все равно будет заблокирован до тех пор, пока системный администратор не убьет связанный с ним процесс:
СОВЕТ. Другие возможные ограничения, сделанные ulimit, задокументированы в файле limits.conf.
Другие инструменты Linux для управления процессами
В дополнение к инструментам, обсуждавшимся ранее, системному администратору также может потребоваться:
a) Изменить приоритет выполнения (использование системных ресурсов) процесса, используя renice. Это означает, что ядро будет выделять больше или меньше системных ресурсов для ограничения процесса на основе назначенного приоритета (число, обычно известное как «nice» в диапазоне от -20 до 19).
Чем ниже значение, тем выше приоритет выполнения. Обычные пользователи могут изменять приоритет только тех процессов, которыми они владеют, и то только на более высокое значение nice (что означает более низкий приоритет выполнения), тогда как root может изменять это значение для любого процесса и может увеличивать или уменьшать его.
Основной синтаксис renice выглядит следующим образом:
Если аргумент после нового значения приоритета отсутствует, по умолчанию он установлен в значение PID. В этом случае для ограничения процесса с идентификатором PID устанавливается значение <новый приоритет>.
б) Прервать выполнение процесса. Этот процесс обычно называют «kill». Это означает, что процессу посылается сигнал, чтобы закончить его выполнение должным образом и освободить любые использованные им ресурсы.
Чтобы завершить процесс, используйте команду kill следующим образом:
Кроме того, вы можете использовать pkill для завершения всех процессов данного пользователя (-u) или владельца группы (-G) или даже тех процессов, у которых есть общий идентификатор PPID (-P). За этими параметрами может следовать числовое представление или фактическое имя в качестве идентификатора:
Например:
Данная команда завершит все процессы, принадлежащие группе GID = 1000.
А команда:
будет завершать все процессы, PPID которых 4993.
Прежде чем запускать pkill, рекомендуется сначала проверить результаты с помощью pgrep, используя опцию -l, а также просмотреть имена процессов. Команда pgrep принимает те же параметры, но возвращает только PID процессов (без каких-либо дальнейших действий), которые могут завершить процессы, так как если используется pkill.
Пример такого выполнения показан на следующем скриншоте:

Итоги
В этой статье мы рассмотрели несколько способов мониторинга использования ресурсов, чтобы проверить целостность и доступность критически важных аппаратных и программных компонентов в системе Linux.
Мы также узнали, как принимать соответствующие меры (либо путем корректировки приоритета выполнения данного процесса, либо путем его прекращения) при необычном поведении любого из процессов.
Мы надеемся, что концепции, объясненные в этой статье, были полезны для вас.
Спасибо за уделенное время на прочтение статьи!
Если возникли вопросы, задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!
Чтобы знать больше и выделяться знаниями среди толпы IT-шников, записывайтесь на курсы Cisco, курсы по кибербезопасности, полный курс по кибербезопасности от Академии Cisco, курсы Linux от Linux Professional Institute на платформе SEDICOMM University (Университет СЭДИКОММ).
Курсы Cisco, Linux, кибербезопасность, DevOps / DevNet, Python с трудоустройством!
- Поможем стать экспертом по сетевой инженерии, кибербезопасности, программируемым сетям и системам и получить международные сертификаты Cisco, Linux LPI, Python Institute.
- Предлагаем проверенную программу с лучшими учебниками от экспертов из Cisco Networking Academy, Linux Professional Institute и Python Institute, помощь сертифицированных инструкторов и личного куратора.
- Поможем с трудоустройством и стартом карьеры в сфере IT — 100% наших выпускников трудоустраиваются.
- Проведем вечерние онлайн-лекции на нашей платформе.
- Согласуем с вами удобное время для практик.
- Если хотите индивидуальный график — обсудим и реализуем.
- Личный куратор будет на связи, чтобы ответить на вопросы, проконсультировать и мотивировать придерживаться сроков сдачи экзаменов.
- Всем, кто боится потерять мотивацию и не закончить обучение, предложим общение с профессиональным коучем.
- отредактировать или создать с нуля резюме;
- подготовиться к техническим интервью;
- подготовиться к конкурсу на понравившуюся вакансию;
- устроиться на работу в Cisco по специальной программе. Наши студенты, которые уже работают там: жмите на #НашиВCisco Вконтакте, #НашиВCisco Facebook.






















