

Утилита uniq — инструмент командной строки Linux, который используется для фильтрации и отображения уникальных строк из входных данных. Ее часто применяют в сочетании с другими командами или в качестве части конвейера. Основная функция uniq — оставить в файле только уникальные строки, удалив все дубликаты.
В этой статье мы покажем, как использовать команду uniq в ОС Linux.
Содержание:
Синтаксис команды uniq
Команда uniq имеет достаточно простой синтаксис, который выглядит следующим образом:
Где:
[options]— необязательные опции, которые изменяют поведение команды;[input_file]— название входного файла, строки которого должна обработать командаuniq(если входной файл не указан, утилита считывает данные из стандартного ввода);[output_file]— название выходного файла, куда будут записаны строки после обработки (если он не указан,uniqвыведет результаты в терминал).
Далее мы покажем примеры использования uniq со следующими опциями:
-c— подсчитывает, сколько раз строка встречается во входных данных;-i— указывает команде игнорировать регистр входных данных;-d— отображает только строки, которые повторяются;-D— показывает повторяющиеся строки с их дубликатами;--all-repeated— разделяет повторяющиеся строки абзацами;--group— группирует входные данные и разделяет их абзацами;-u— отображает только уникальные строки во входных данных.
Читайте также: 10 полезных приемов для терминала Linux.

Использования команды uniq в ОС Linux
В качестве примера мы будем использовать файл 123.txt. Выведем его содержимое на экран с помощью команды cat:
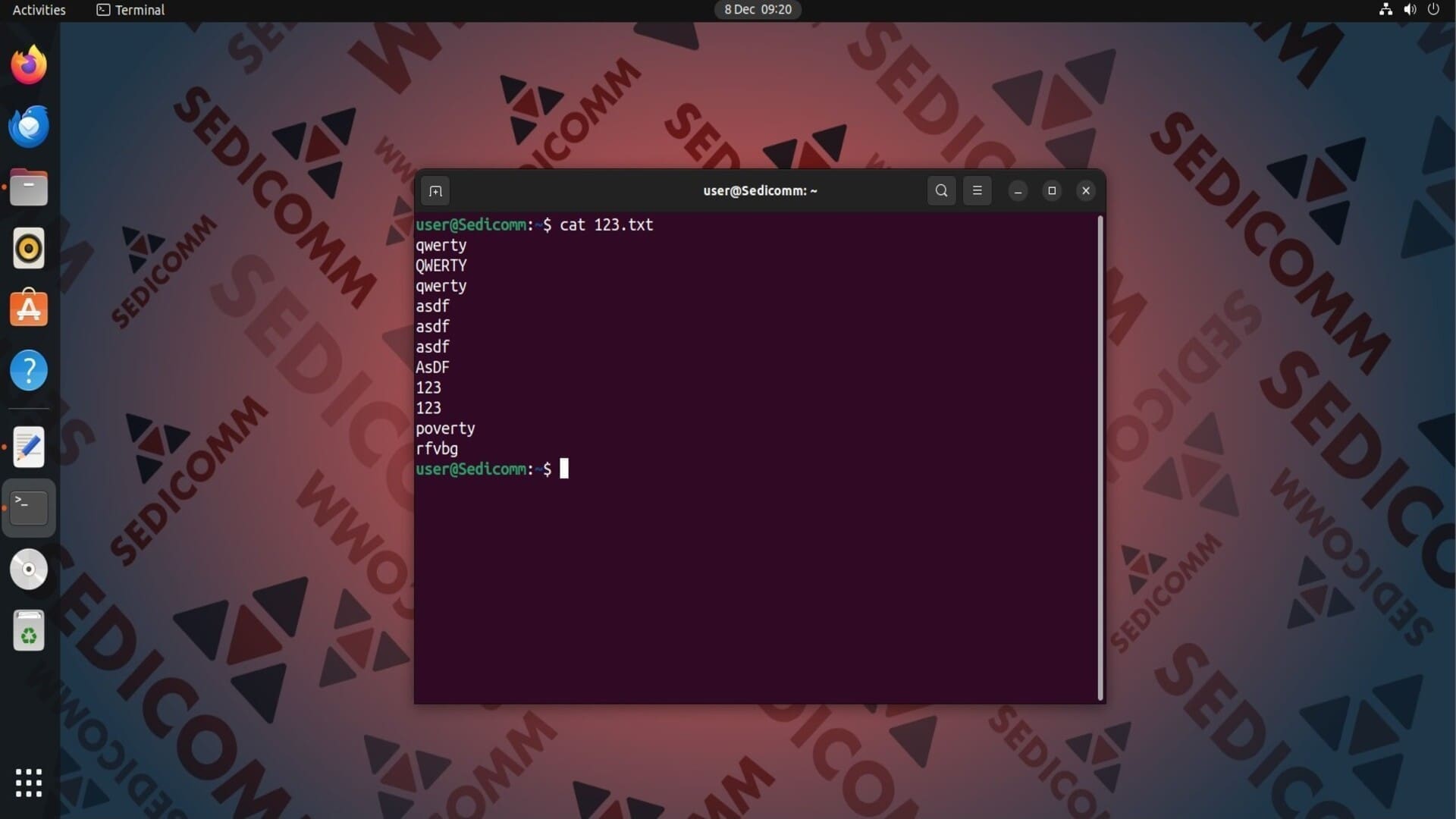
Удаление смежных дублирующихся строк
Если выполнить команду uniq без каких-либо опций, она удалит все соседние повторяющиеся строки. Например:
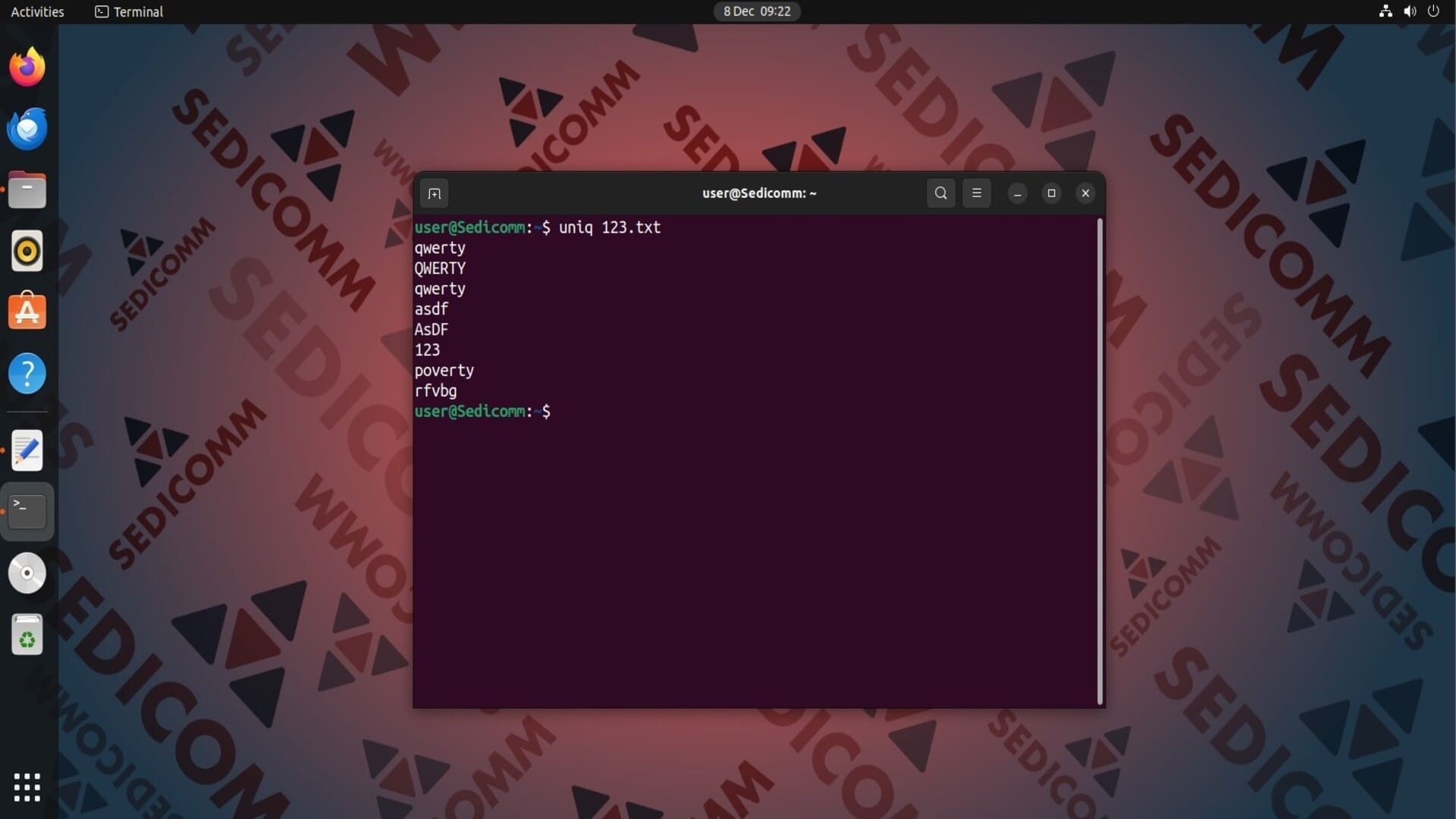
На скриншоте выше видно, что в результате вывода команды присутствуют две строки qwerty. Чтобы удалить все повторяющиеся строки, для начала отсортируйте содержимое файла с помощью sort, а затем примените команду uniq:
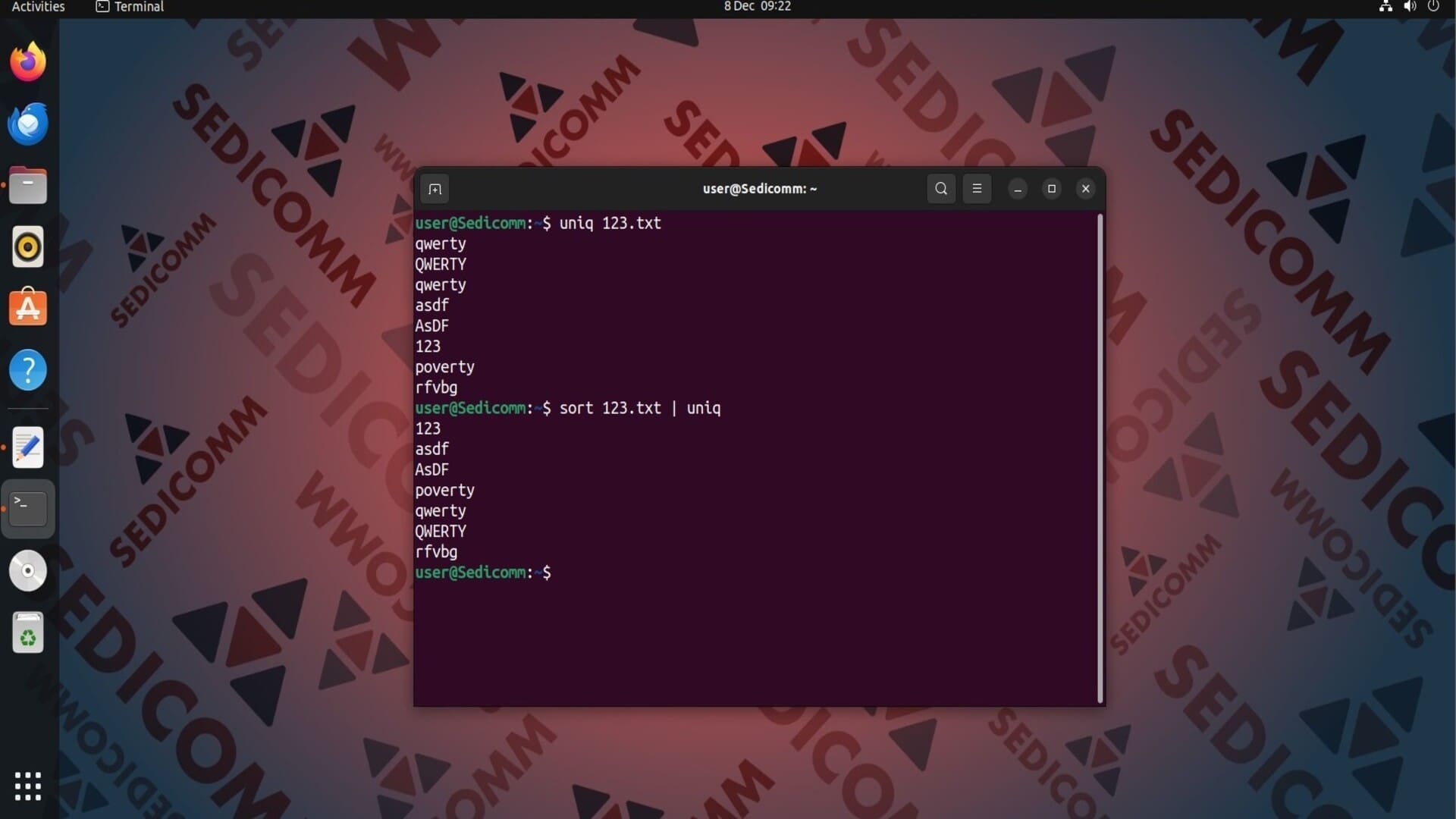
Читайте также: Как использовать sort в Linux — часть 1.

Подсчет дублирующихся строк
Параметр -c позволяет узнать, сколько строк из входных данных повторяются. К примеру:
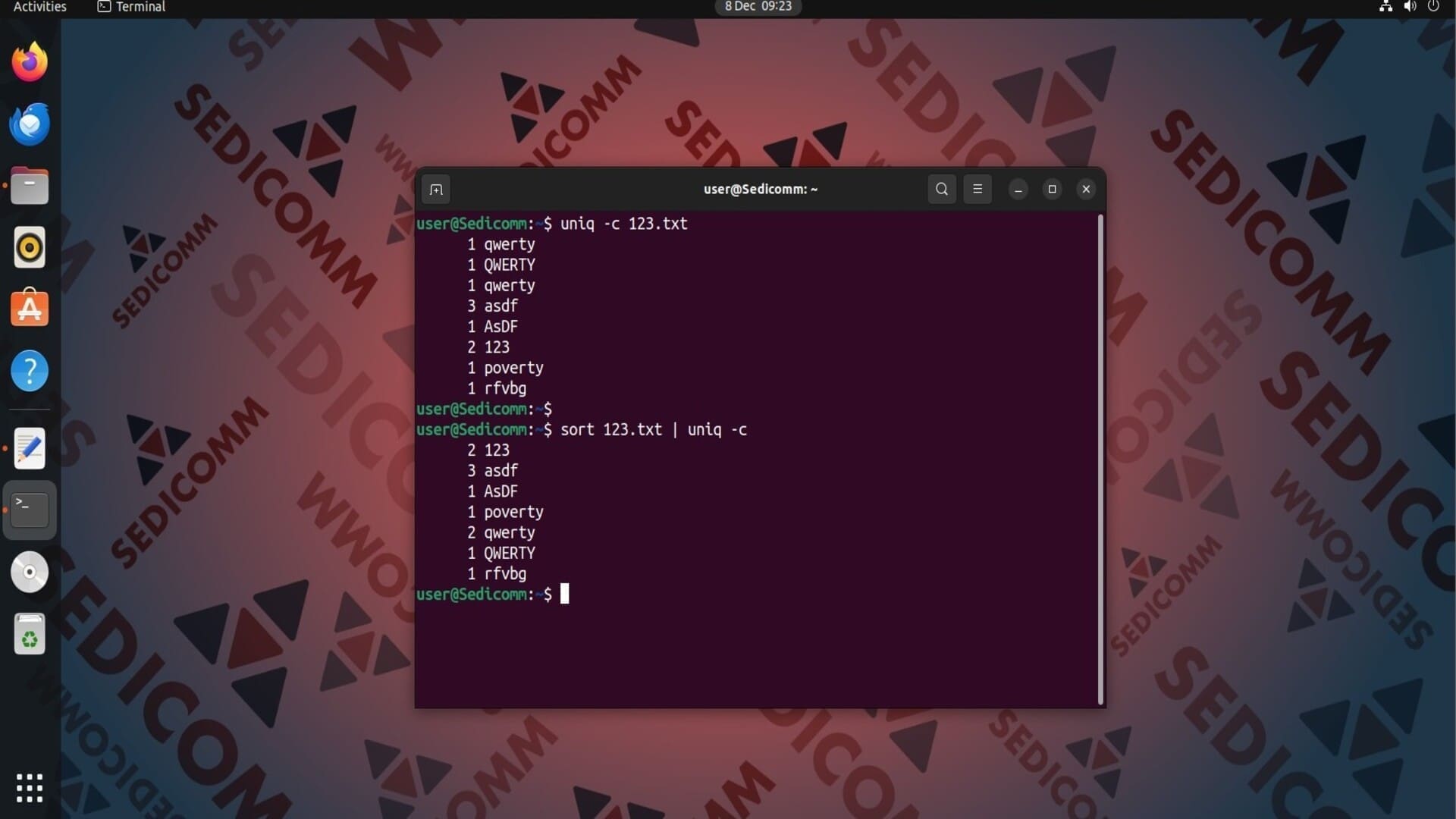
Важно: использование sort помогает более точно определить количество повторяющихся строк.
Удаление повторяющихся строк с учетом регистра
В нашем тренировочном файле есть одинаковые слова, которые содержат символы разного регистра. По умолчанию uniq принимает их за разные слова. Вы можете указать команде игнорировать регистр букв с помощью опции -i:
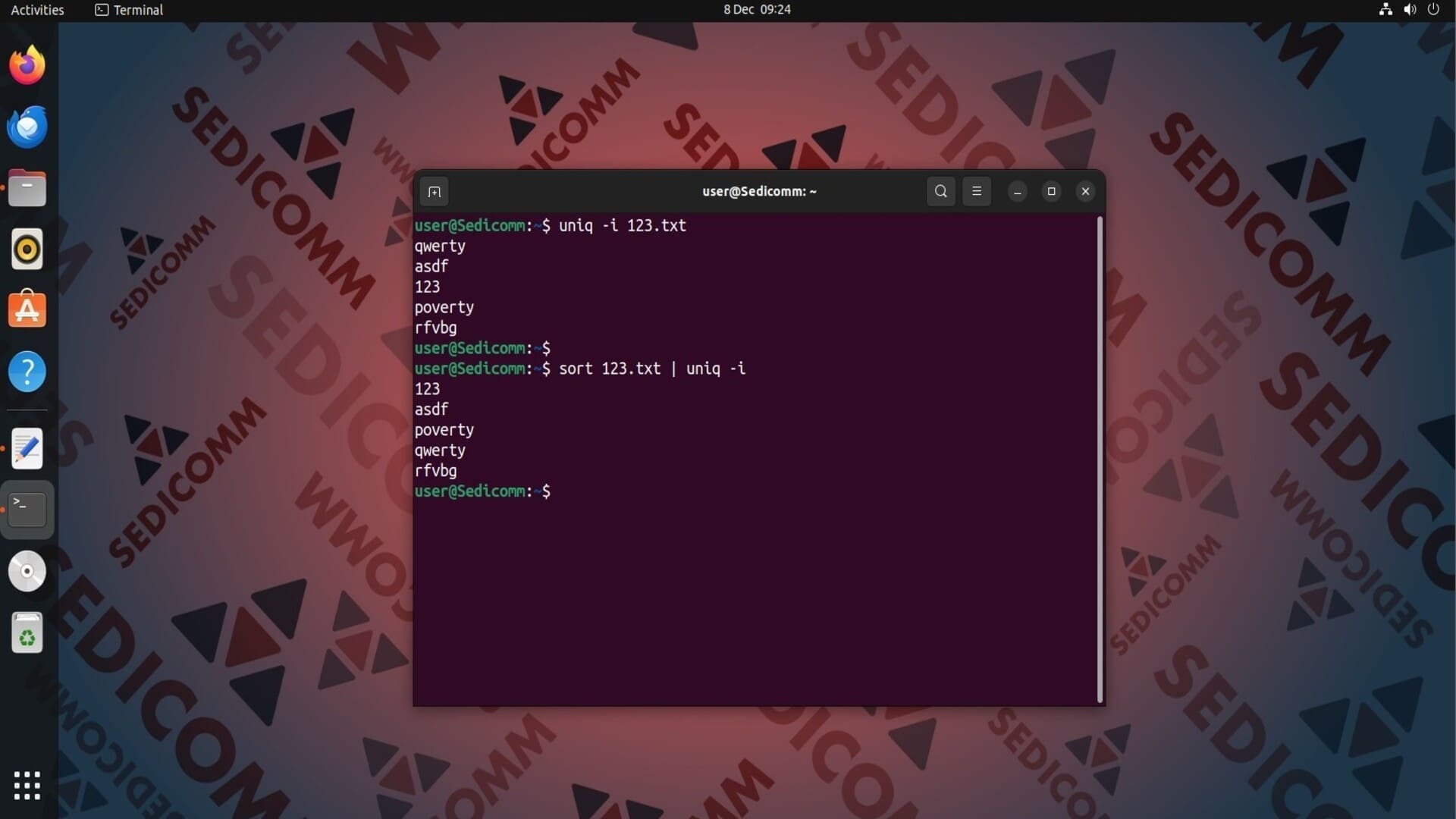
Читайте также: 13 примеров команды cat для начинающих в Linux.
Отображение только дублирующихся строк
Чтобы узнать, какие строки повторяются в текстовом файле, выполните команду uniq с параметром -d. Например:
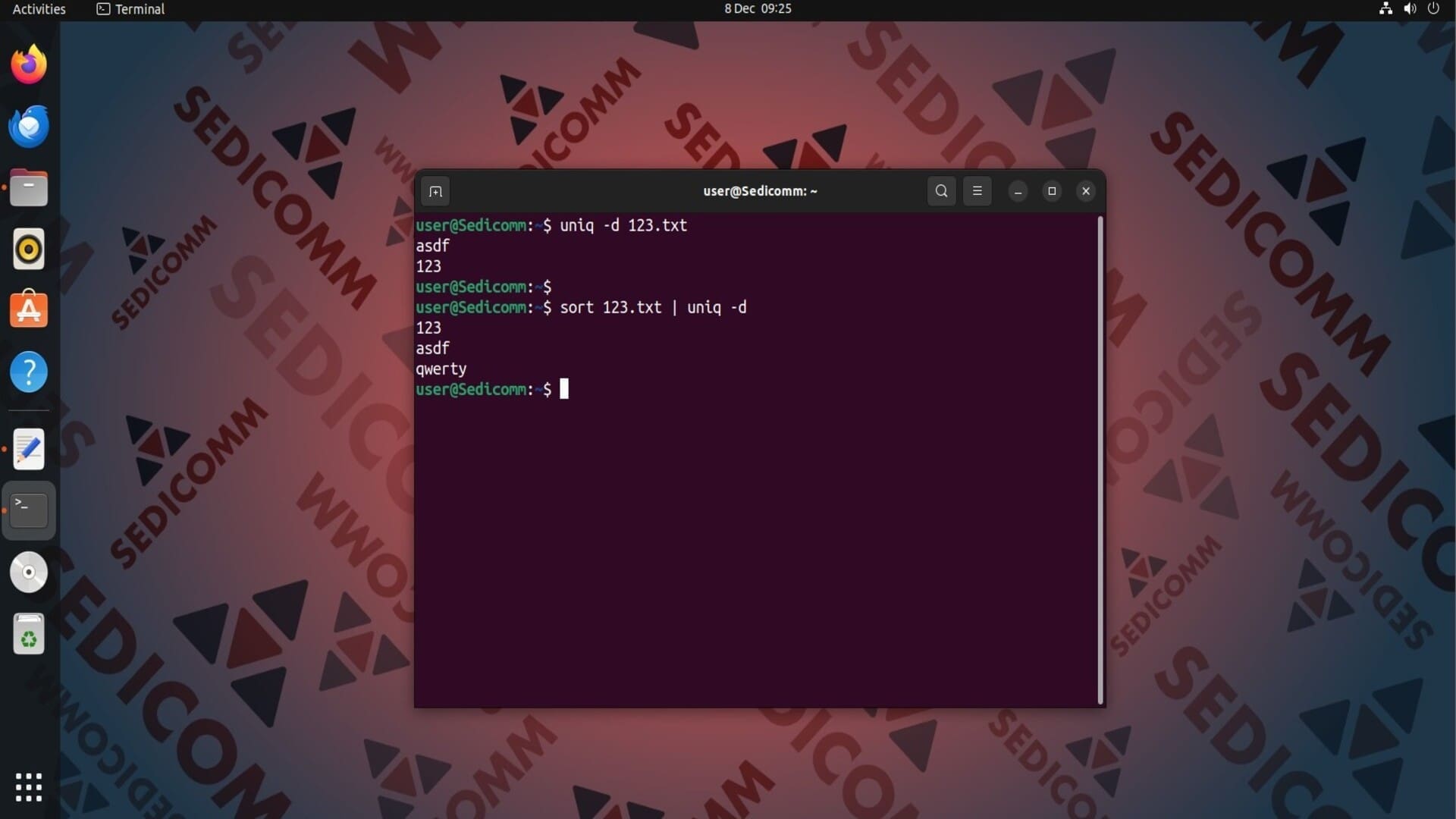
На скриншоте выше видно, что команда вывела на экран только слова, которые повторяются. Если Вам нужно отобразить на экране эти строки вместе с их дубликатами, используйте опцию -D:
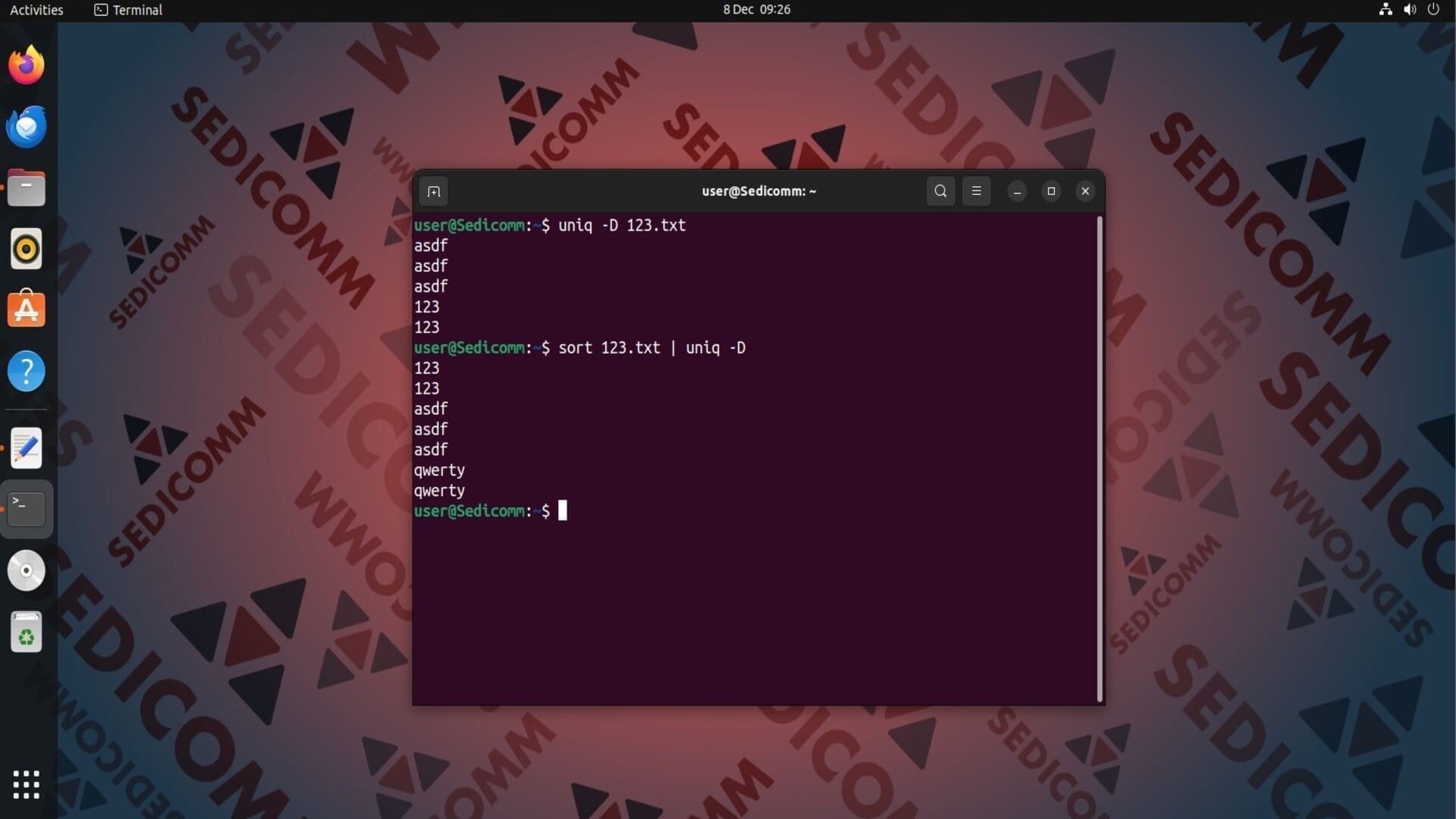
Разделение дублирующихся строк абзацами
Утилита uniq позволяет форматировать ее вывод. Например, Вы можете разделить группы повторяющихся строк абзацами. Для этого следует использовать параметр --all-repeated со значением separate:
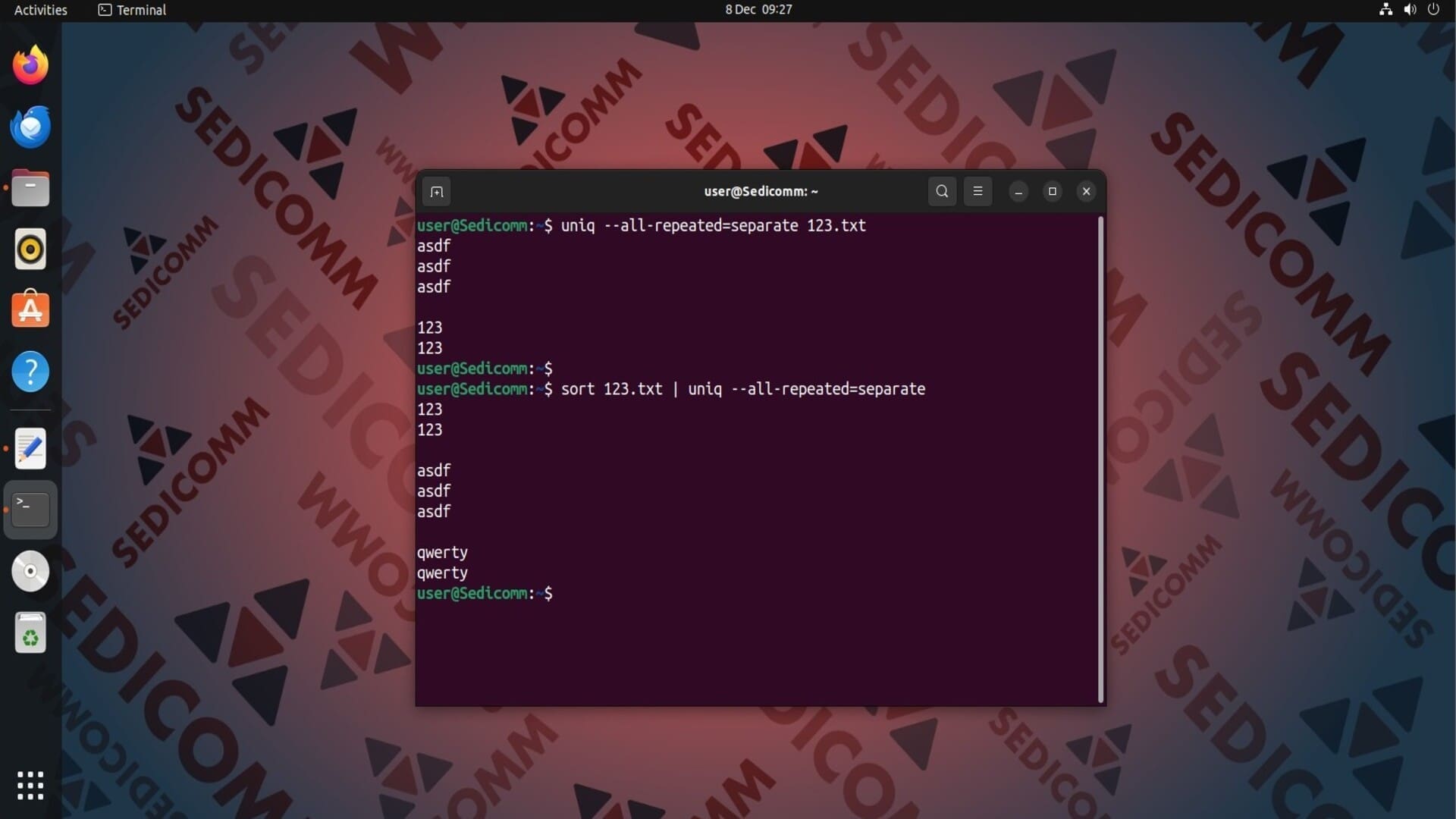
Если Вам в результате также нужно оставить уникальные строки, замените параметр --all-repeated на --group:
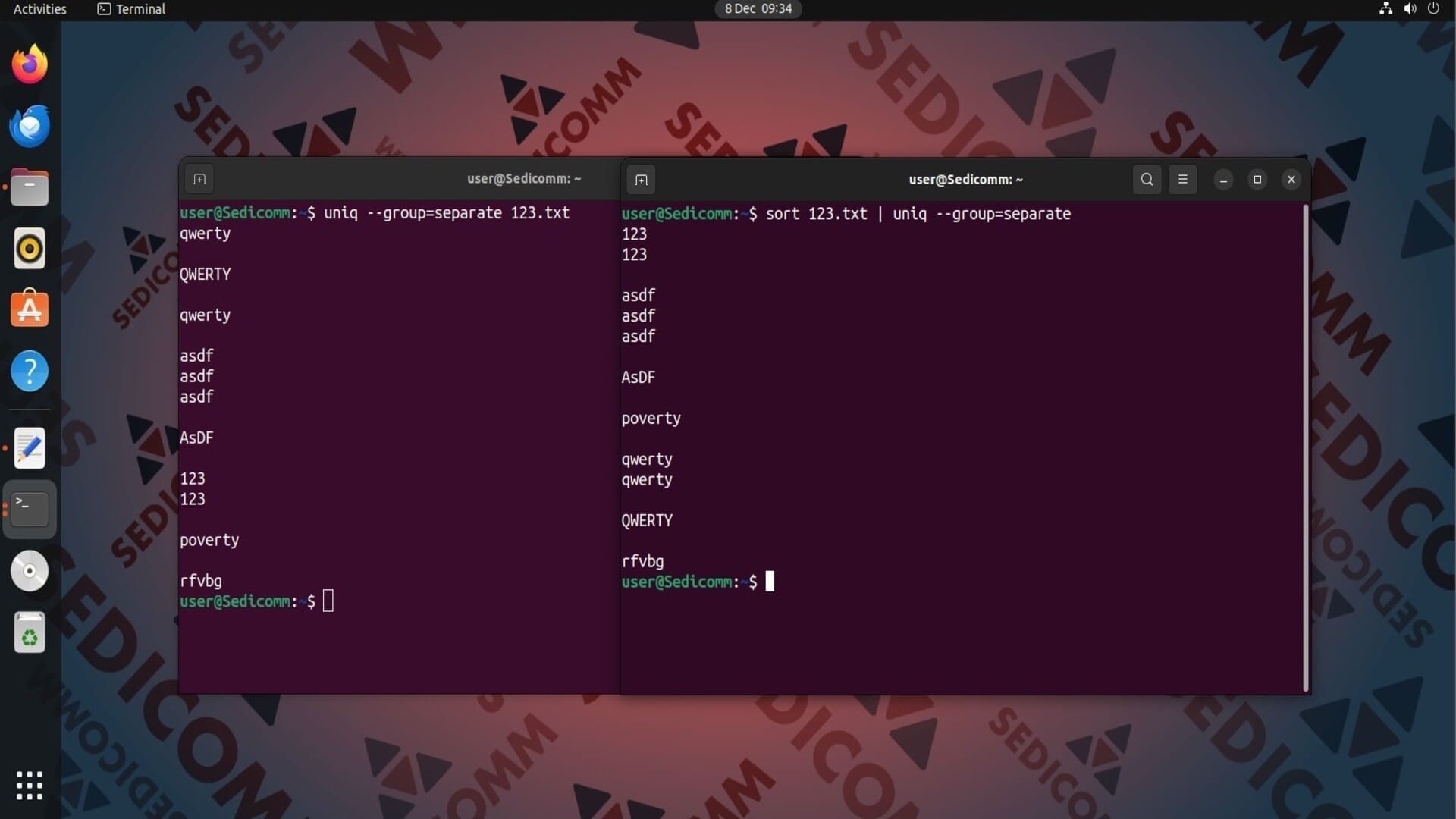
Читайте также: 15 примеров команды ls в Linux.
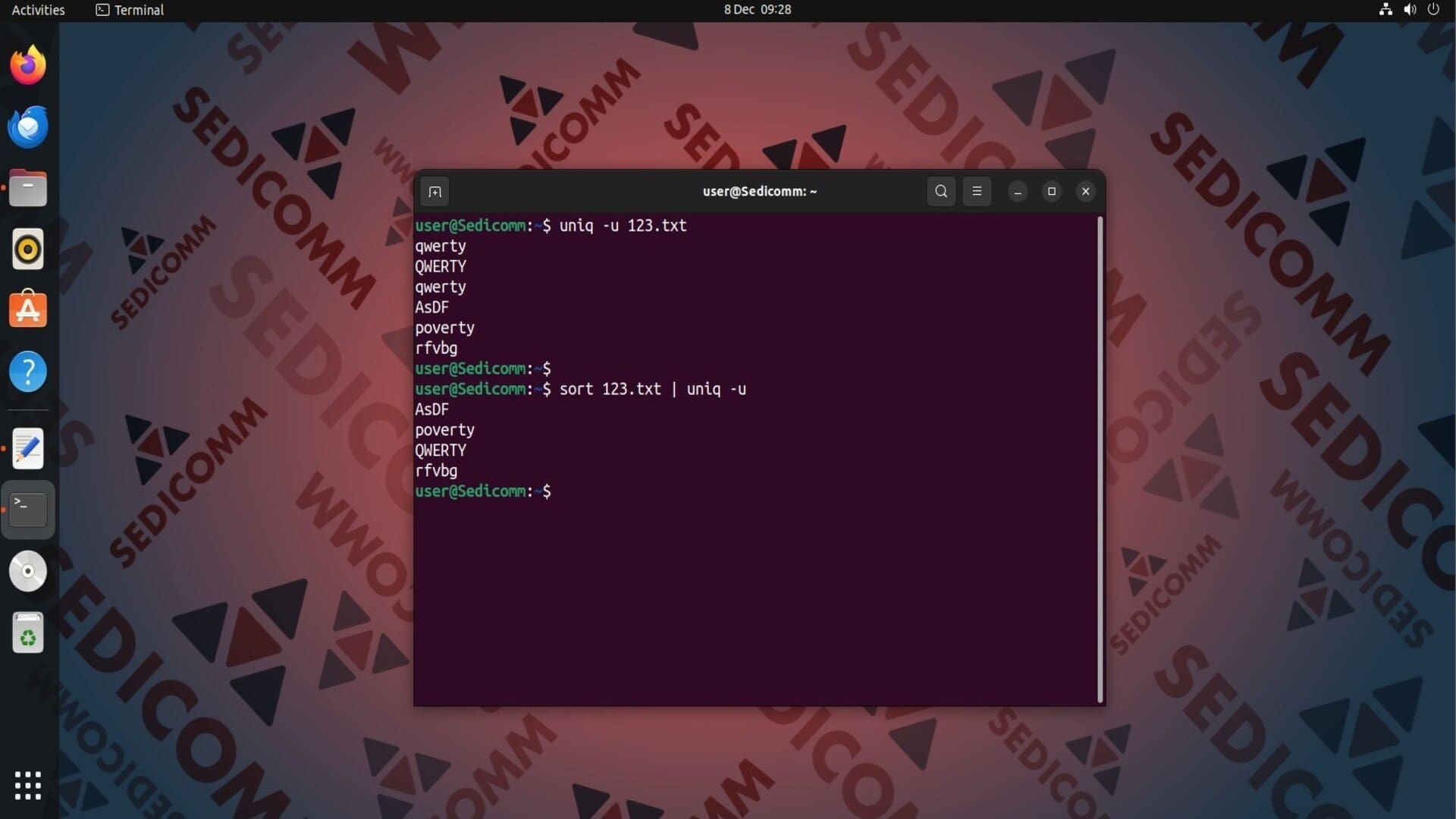
Вывод уникальных строк из входных данных
Вы можете узнать, какие строки из входных данных не повторяются. Для этого примените команду uniq с опцией -u:
Выводы
Теперь Вы знаете, как использовать команду uniq с различными опциями для удаления повторяющихся строк из входных данных. Показанные в этой статье примеры помогут Вам при обработке текста в командной строке Linux.
Спасибо за время, уделенное прочтению статьи!
Если возникли вопросы — задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!
Чтобы знать больше и выделяться знаниями среди толпы IT-шников, записывайтесь на курсы Cisco, курсы по кибербезопасности, полный курс по кибербезопасности, курсы DevNet / DevOps (программируемые системы) от Академии Cisco, курсы Linux от Linux Professional Institute на платформе SEDICOMM University (Университет СЭДИКОММ).
Курсы Cisco, Linux, кибербезопасность, DevOps / DevNet, Python с трудоустройством!
- Поможем стать экспертом по сетевой инженерии, кибербезопасности, программируемым сетям и системам и получить международные сертификаты Cisco, Linux LPI, Python Institute.
- Предлагаем проверенную программу с лучшими учебниками от экспертов из Cisco Networking Academy, Linux Professional Institute и Python Institute, помощь сертифицированных инструкторов и личного куратора.
- Поможем с трудоустройством и стартом карьеры в сфере IT — 100% наших выпускников трудоустраиваются.
- Проведем вечерние онлайн-лекции на нашей платформе.
- Согласуем с вами удобное время для практик.
- Если хотите индивидуальный график — обсудим и реализуем.
- Личный куратор будет на связи, чтобы ответить на вопросы, проконсультировать и мотивировать придерживаться сроков сдачи экзаменов.
- Всем, кто боится потерять мотивацию и не закончить обучение, предложим общение с профессиональным коучем.
- отредактировать или создать с нуля резюме;
- подготовиться к техническим интервью;
- подготовиться к конкурсу на понравившуюся вакансию;
- устроиться на работу в Cisco по специальной программе. Наши студенты, которые уже работают там: жмите на #НашиВCisco Вконтакте, #НашиВCisco Facebook.



















