

Linux Foundation — некоммерческая организация, которая занимается подготовкой и сертификацией специалистов LFCS (Linux Foundation Certified Sysadmin). В рамках 1 из 20 уроков по подготовке к экзаменам Linux Foundation Вы узнаете о том, какие команды помогут обрабатывать текстовые потоки и для решения каких задач в целом используется обработка текстовых потоков в Linux.
Полный список уроков для прохождения индустриальной сертификации: Курс LFCS (Linux Foundation Certified Sysadmin): программа подготовки к экзаменам..
Содержание:
- Создаем каталог для выполнения практических примеров
- Как устроена обработка текстовых потоков в Linux
- Команды для обработки стандартных потоков
- Выводы
Создаем каталог для выполнения практических примеров
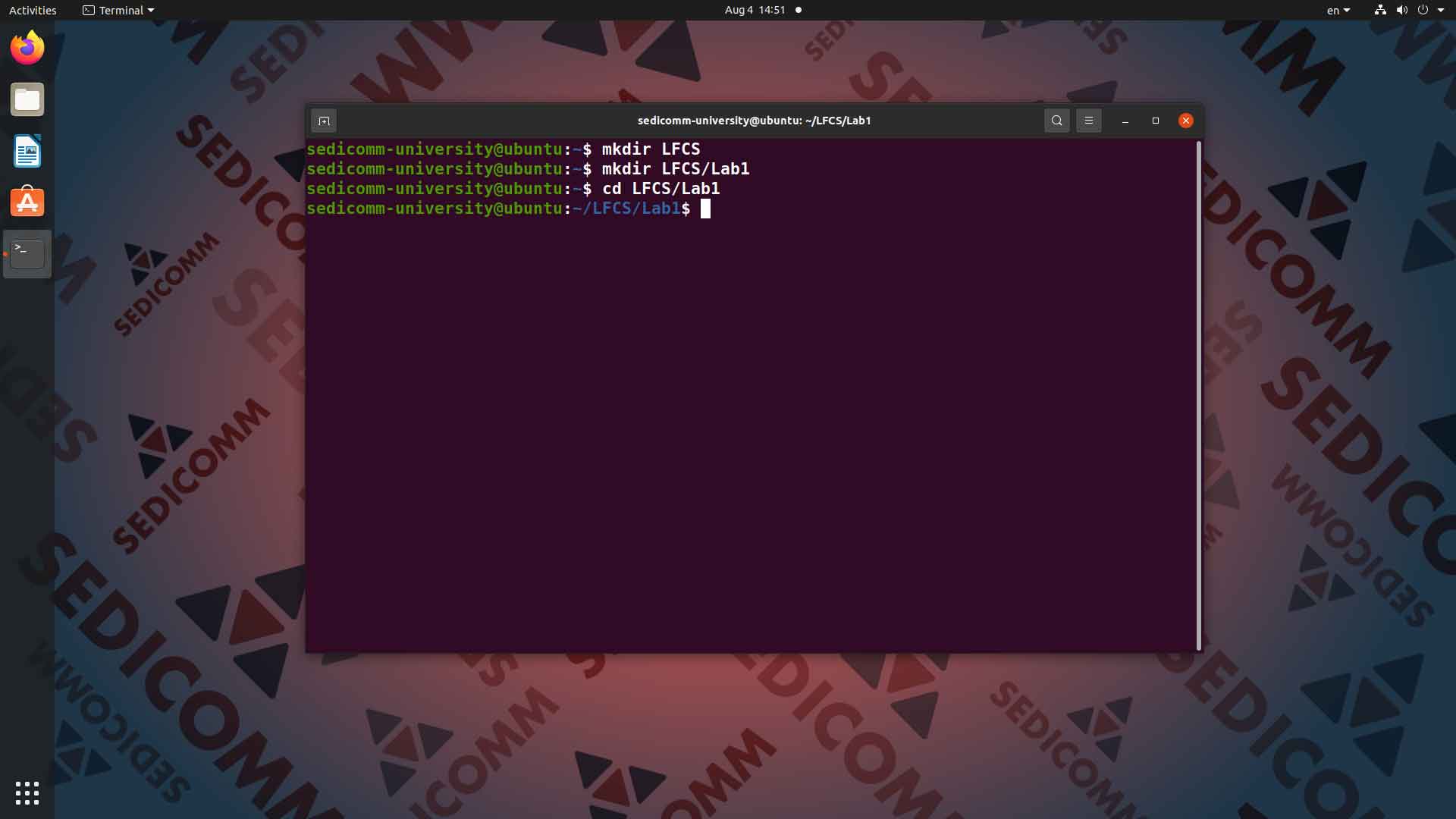
Давайте создадим рабочий каталог Linux, в котором Вы будете практиковаться. Для этого вводим в командную строку команды mkdir LFCS, потом mkdir LFCS/Lab1:
В результате Вы создали общий каталог LFCS, в котором находится подкаталог для практических работ в рамках первого занятия — Lab1. Теперь Вам нужно перейти в него. Для этого вводим в командную строку команду cd LFCS/Lab1:
Теперь можно начинать урок и знакомиться с обработкой текстовых потоков в Linux.

Как устроена обработка текстовых потоков в Linux
UNIX-подобные операционные системы (в том числе — из семейства GNU / Linux) обрабатывают ввод и вывод программ в виде последовательностей символов — потоков. Всего существует три вида стандартных потоков:
- стандартный ввод (поток 0 —
stdin); - стандартный вывод (поток 1 —
stdout); - стандартный вывод ошибок (поток 2 —
stderr).
Стоит отметить, что стандартные потоки по факту считаются отдельными специальными файлами ( по соглашению в UNIX и Linux).
В рамках этой статьи мы прежде всего рассмотрим использование обработки потока 1 (stdout) — стандартного вывода. При этом в работе с ОС широко используются два инструмента, позволяющих обрабатывать этот поток:
- перенаправление (с помощью специального символа
>); - конвейер (с помощью специального символа
|);
Теперь давайте разберемся, чем именно они отличаются на практике.
Перенаправление (>) — это команда, позволяющая записать результат стандартного вывода предыдущей команды в указанный файл. Синтаксис команды перенаправления вывода выглядит следующим образом:
Важно: команда > без предупреждения перезаписывает содержимое файла каждый раз. Если Вы хотите вместо этого дополнять содержимое файла — используйте команду >>.
Конвейер (|) — это команда, которая автоматически перенаправляет результат стандартного вывода предыдущей команды в качестве ввода следующей команды без использования каких-либо промежуточных файлов. Синтаксис команды конвейера выглядит следующим образом:

Важно: последовательность команд, объединенных с помощью конвейера, позволяет автоматизировать рутинные операции и создать длинные цепочки действий.
Команды для обработки стандартных потоков
В рамках этого урока Вы научитесь использовать следующие команды, созданные для обработки стандартных потоков Linux:
sed;sortиuniq;grep;tr;cut.
С их помощью можно выполнять различные операции с текстовыми данными — фильтровать вывод, удалять ненужные значения, заменять отдельные символы и целые слова. Теперь давайте перейдем к изучению возможностей каждой из команд.
Учимся использовать команду sed
Команда sed — это то, о чем Вас могут спросить в первую очередь на экзамене для сертификации LFCS. Потому давайте сначала рассмотрим ее использование в рамках нашей темы.
Утилита sed — это язык программирования и одновременно текстовый редактор, разработанный для командной строки UNIX-подобных операционных систем (на сегодняшний день использовать sed можно и в других семействах ОС). Основное назначение sed — преобразование текстовых данных стандартного потока.
Наиболее распространенным и простым примером использования команды sed, с помощью которого выполняется обработка текстовых потоков в Linux, является замена символов.
Заменяем нижний регистр символа на верхний с помощью команды sed
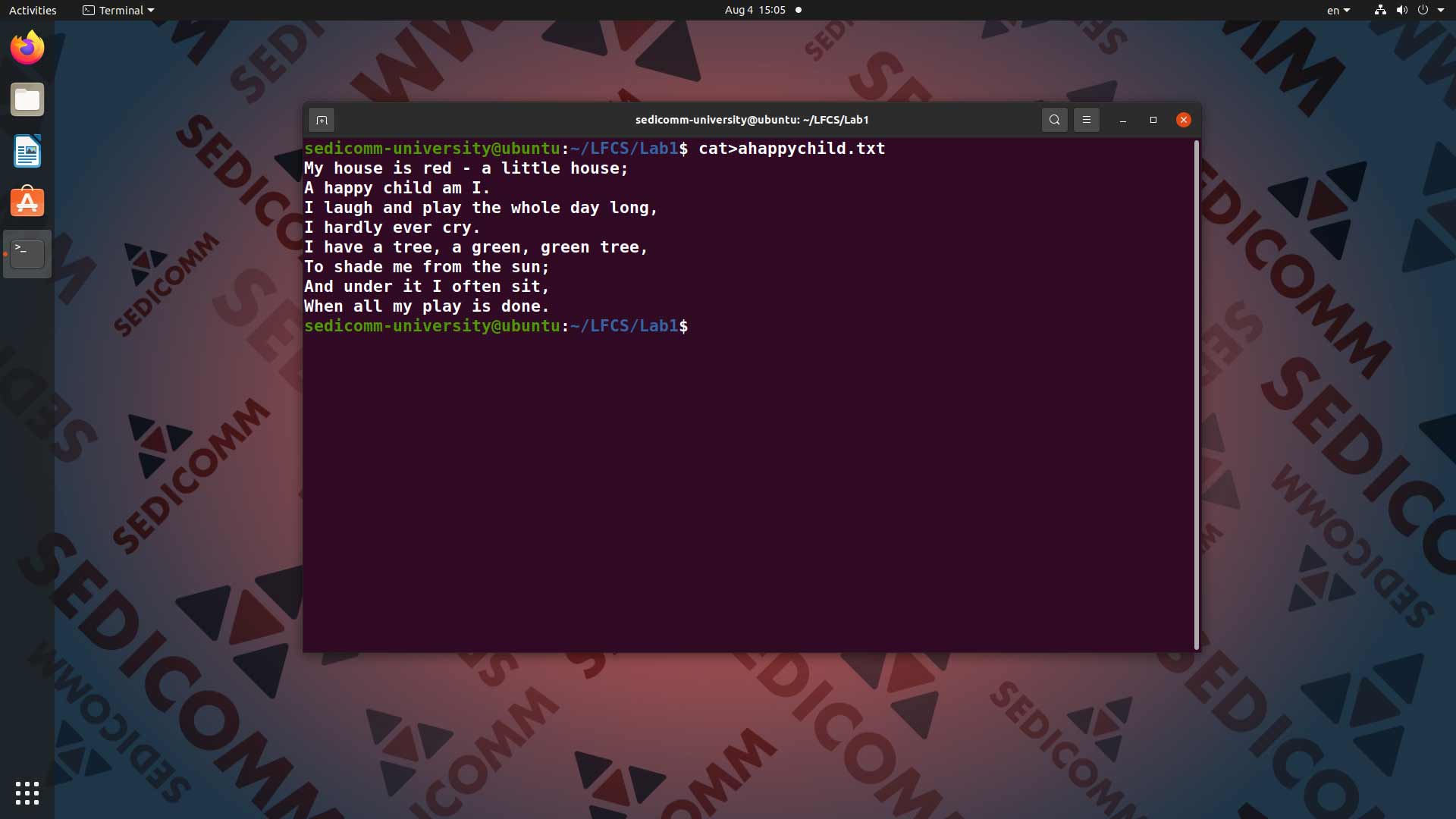
В качестве первого примера мы будем использовать стихотворение анонимного автора под названием A happy child. Чтобы создать соответствующий текстовый файл — вводим в командную строку команду cat>ahappychild.txt:
Как видите, мы воспользовались перенаправлением потока вывода команды cat в файл. Теперь просто вводим текст стихотворения, не забывая переносить новые строки клавишей Enter. Чтобы закончить перенаправление текста в файл — воспользуемся комбинацию клавиш Ctrl+D.
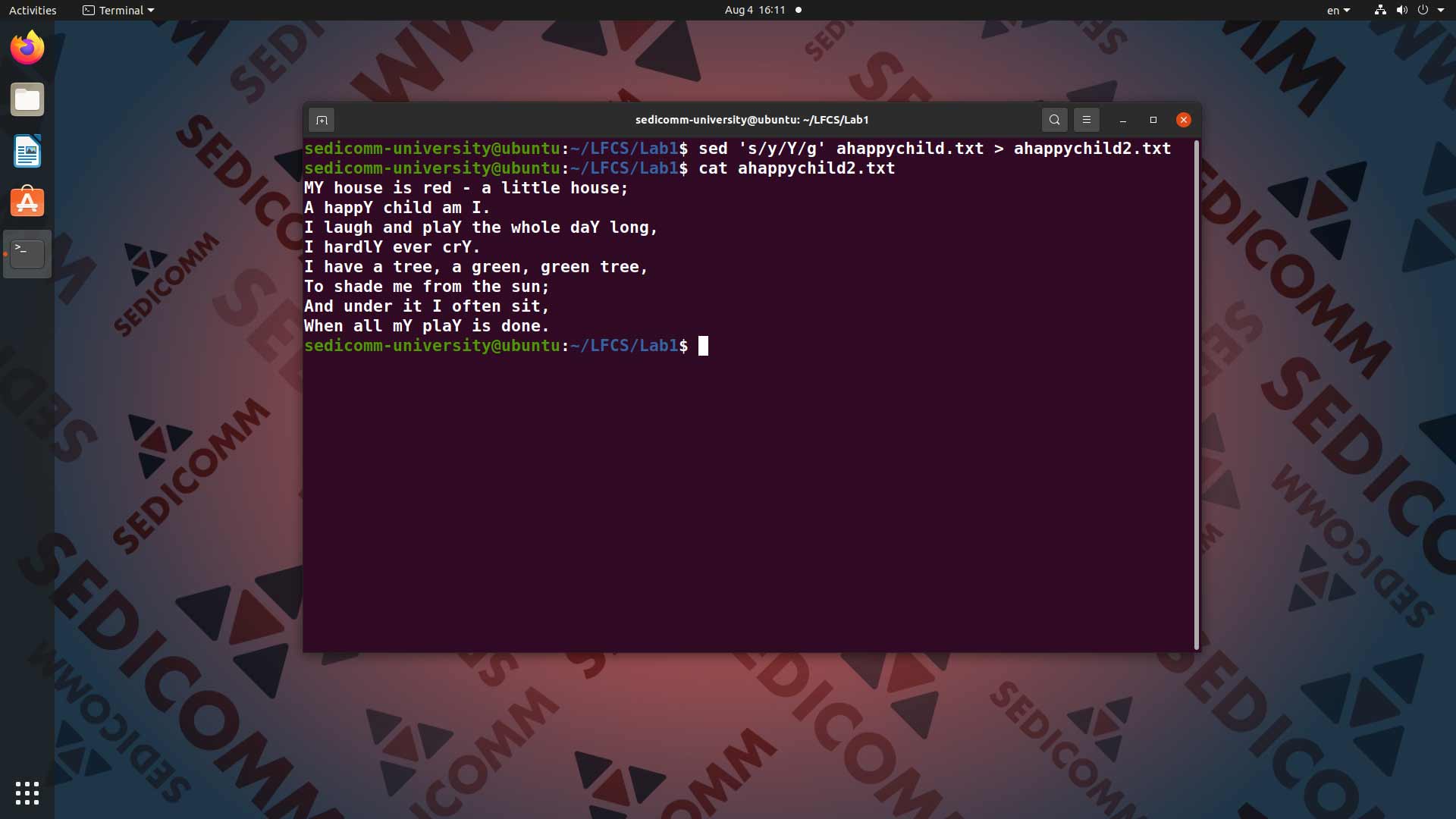
Для начала давайте попробуем изменить регистр символа с нижнего на верхний — например, заменить в нашем файле у на Y. И перенаправить вывод команды с результатами замены в новый текстовый файл — ahappychild2.txt. Для этого вводим в командную строку команду sed 's/y/Y/g' ahappychild.txt > ahappychild2.txt:
Вводим в командную строку команду sedicomm-university@ubuntu:~/LFCS/Lab1$ cat ahappychild2.txt, чтобы увидеть результат замены символов:
Теперь давайте разберемся в том, что означают символы, заключенные в одинарные кавычки:
s— выбираем операцию замены символов;y— задаем символ, который хотим заменить;Y— задаем символ, на который хотим заменить;g— указываем командеsedзаменить все совпадающие символы по тексту, а не только первый (в противном случае будет заменено лишь первое вхождение символа).
Заменяем слово на специальный символ с помощью команды sed
Теперь давайте попробуем заменить не отдельный символ, а целое слово (шаблон). И не на другое слово или просто символ, а на специальный символ.
Специальные символы Linux (метасимволы) — это символы, имеющие особое значение для оболочки Linux. Вместо своего буквального значения метасимволы по умолчанию интерпретируются оболочкой как определенные команды.
Мы уже рассказывали выше о вертикальной черте | (вызывает команду конвейера) и знаке больше > (вызывает команду перенаправления). Помимо этого в качестве примера специальных символов в UNIX-подобных операционных системах можно привести:
.— точку (заменяет любой одиночный символ);\— обратную косую черту (отменяет исполнение идущего за ней специального символа в качестве команды);$— знак доллара (обозначает конец файла или начало строки);^— карет (обозначает начало файла или начало строки);*— звездочку (обозначает произвольное количество повторений предыдущего символа);[и]— квадратные скобки (в них берется множество символов, используемых в качестве шаблона);&— амперсанд (последовательно объединяет отдельные символы или шаблоны);~— тильду (заменяет собой путь до Вашего домашнего каталога).
Есть и другие метасимволы, использующиеся в Linux. Стоит отметить, что их уверенное применение является одной из важных составляющих умения работать с командной строкой операционной системы.
Однако тот факт, что специальные символы имеют особое значения для оболочки Linux, обозначает, что Вы не сможете просто так применять их в качестве шаблона для поиска или замены. Чтобы сделать это — нужно использовать приведенную в качестве примера обратную косую черту (\), отменяющую для оболочки значение следующего за ней метасимвола.
В качестве примера давайте попробуем заменить слово and на & (амперсанд). Кроме того, дополнительно заменим I на You. Но только в том случае, если c I будет начинаться новая строка. Для этого вводим в командную строку команду sed 's/and/\&/g;s/^I/You/g' ahappychild2.txt:
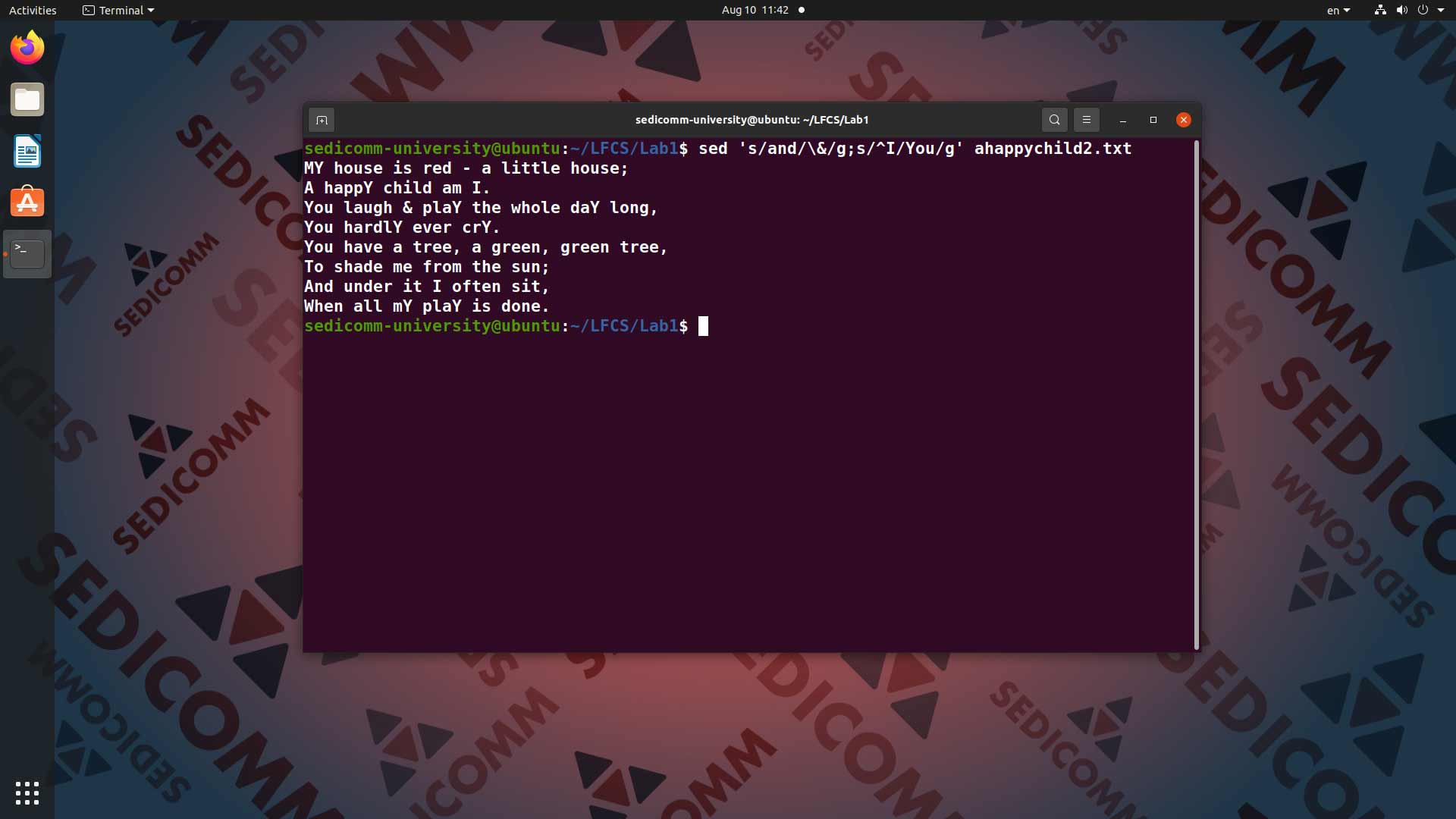
Как видно из этого примера, команда sed позволяет через точку с запятой ; перечислить более одной команды подстановки с применением регулярных выражений. Так Вы с помощью знака «^» добавили замену тех I, которые находятся в начале строки.
Фильтруем текст с помощью команды sed
Помимо всего прочего, команду sed можно использовать для того, чтобы добавить в вывод или убрать из него указанное количество строк файла. В качестве примера возьмем файл /var/log/dpkg.log. Для начала пробуем вывести на экран строки, добавленные 4 августа 2022 года в 13:06. Кроме того, ограничиваем вывод только первыми 5 строчками, соответствующими дате и времени. Для этого вводим в командную строку команду sed -n '/^2022-08-04 13:06/p' /var/log/dpkg.log | sed -n 1,5p:
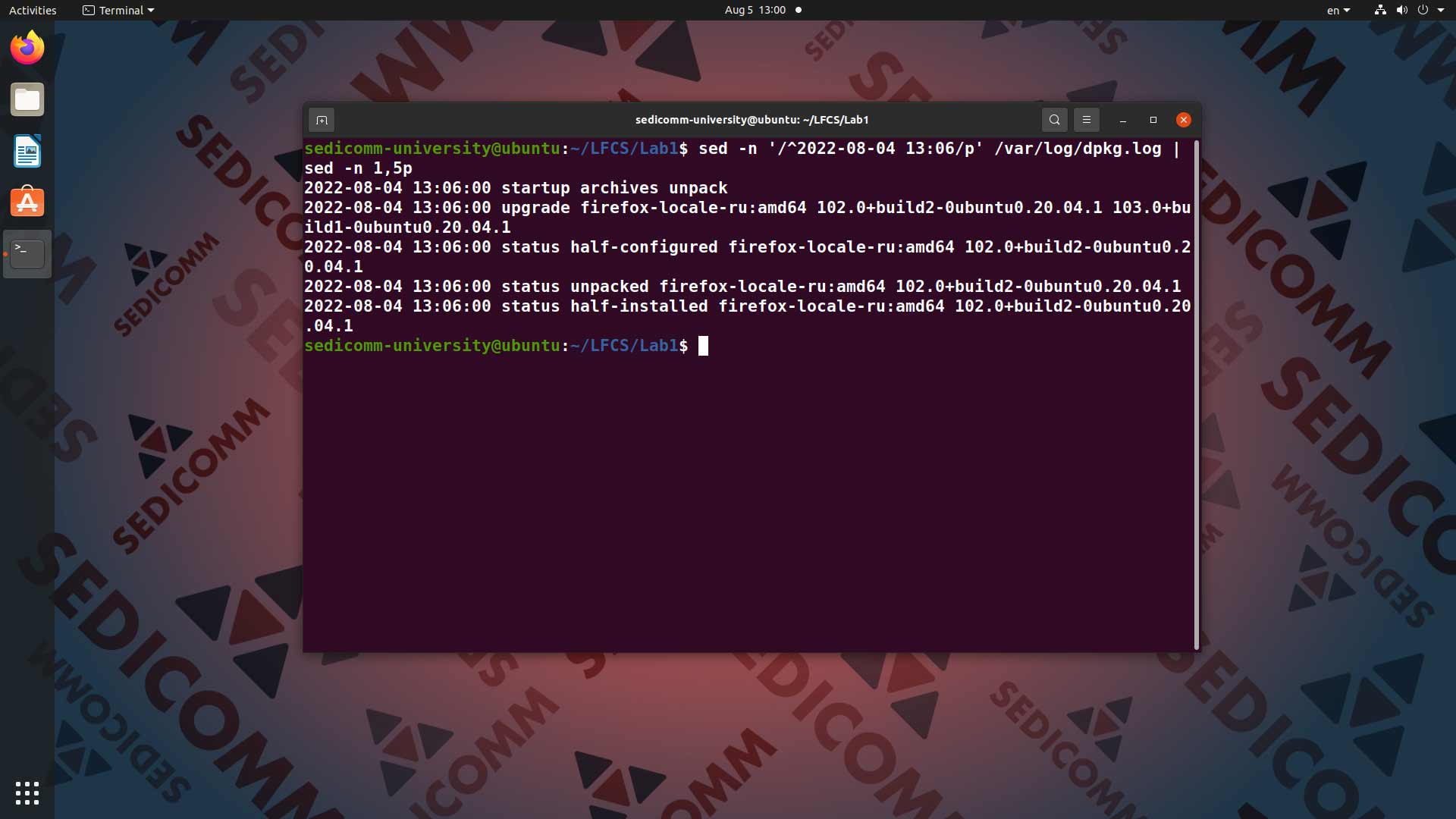
В данном случае команда sed находит все строки, начинающиеся с заданного шаблона — 2022-08-04 13:06. После чего используется знак конвейера |, снова передающий результаты вывода команде sed. Однако в этот раз она применяется для того, чтобы вывести на экран только строки с 1 по 5 из вывода первой команды.
Удаляем комментарии и пустые строки с помощью команды sed
Команда sed позволяет упростить работу с файлами конфигурации или скриптами. В качестве примера возьмем файл /etc/apache2/apache2.conf. По умолчанию он содержит много строк с комментариями и пустых строк, мешающих увидеть нужные Вам настройки. Чтобы убрать из вывода все лишнее — вводим в командную строку команду sed '/^#\|^$/d' /etc/apache2/apache2.conf:
Теперь давайте разберемся, как работают составляющие этой команды:
^#— находит строки с комментариями (которые начинаются с соответствующего специального символа);^$— находит пустые строки;|—разделяет условия поиска логическим ИЛИ (в противном случае критериям поиска будут соответствовать только строки, которые одновременно содержат комментарий и пустые — что в нашем случае невозможно);d— указываем командеsedудалить все строки, соответствующие условиям поиска.
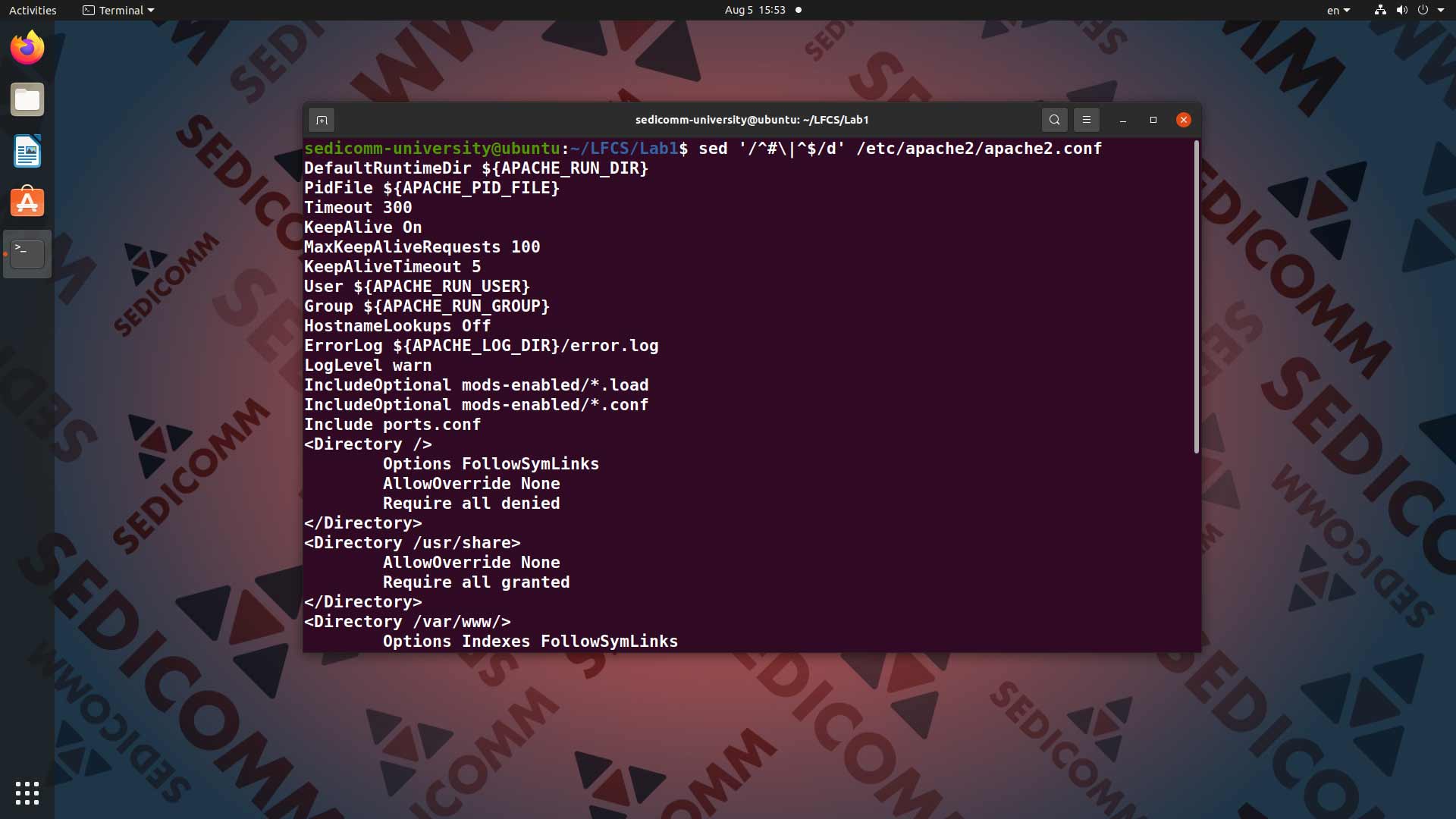
Можно вывести на экран только важную информацию из файла конфигурации или скрипта, либо перенаправить результат в другой файл для дальнейшего использования.
Учимся использовать команду grep
Еще одна крайне полезная команда, которую нужно освоить специалисту LFCS — это grep. С ее помощью выполняется основная обработка текстовых потоков в Linux.
Утилита grep — это инструмент командной строки Linux (а также других UNIX-подобных операционных систем), предназначенный для поиска и вывода на экран текстовой информации, соответствующей заданному регулярному выражению. С помощью команды grep очень удобно осуществлять фильтрацию данных, передаваемых в стандартный вывод (поток 1 — stdout)
Фильтруем вывод с помощью команды grep
Давайте попробуем извлечь данные из файла /etc/passwd. К примеру, строку о пользователе sedicomm-university. Для этого вводим в командную строку команду grep sedicomm-university /etc/passwd:
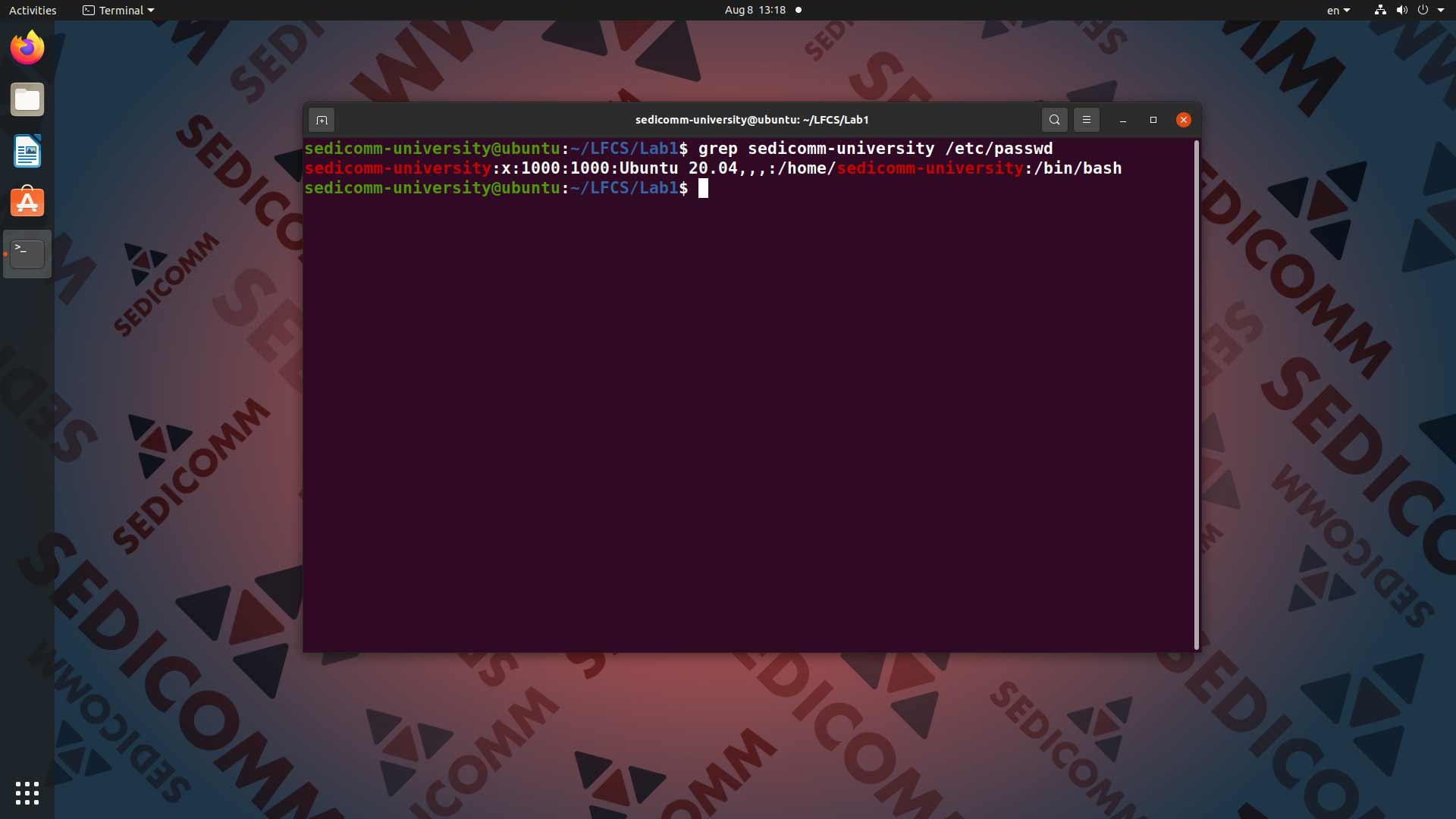
Находим все вхождения комбинации символов с подстановкой любого числа с помощью команды grep
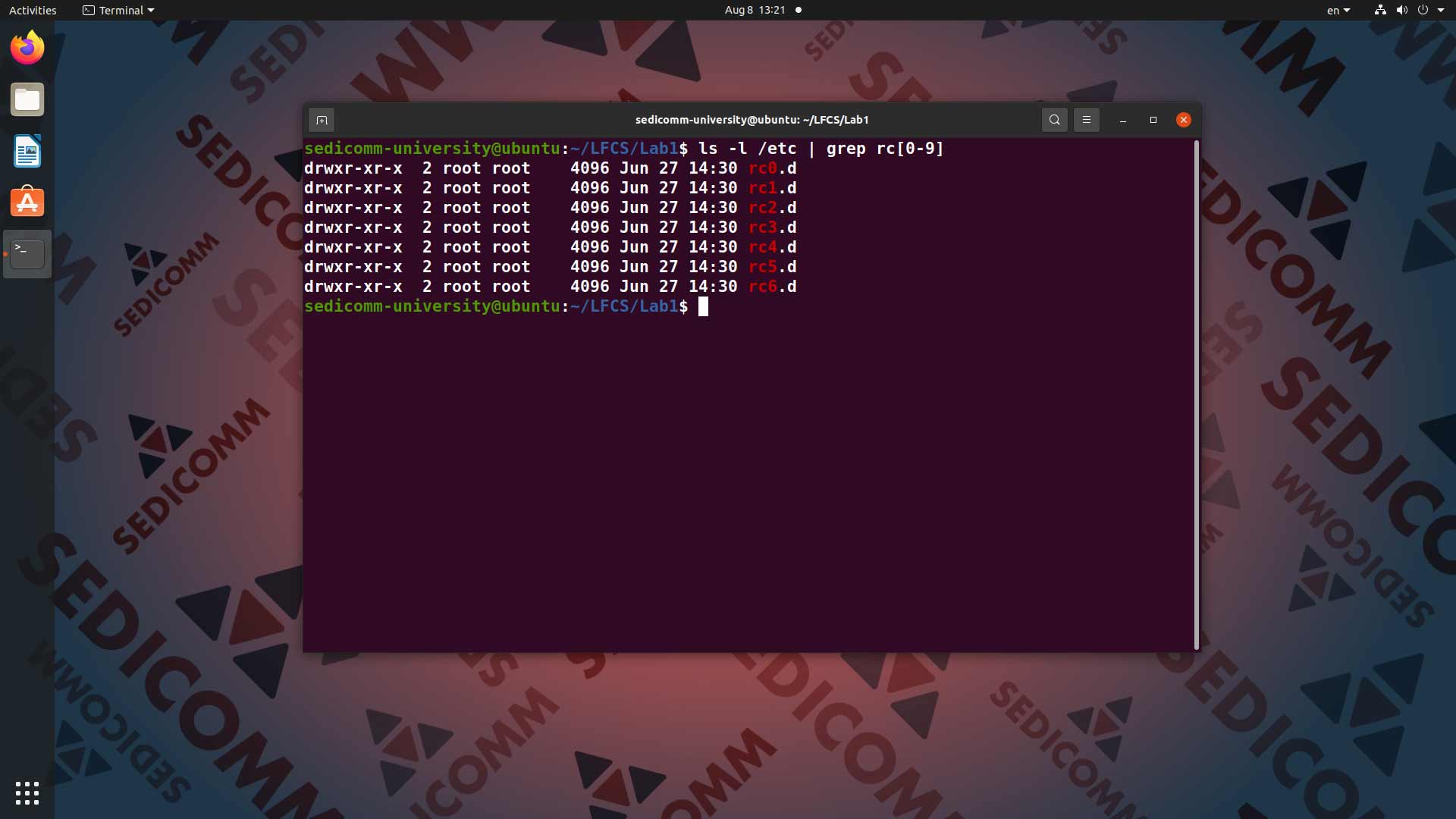
Теперь попробуем немного усложнить задачу. Например, найти в каталоге /etc все файлы, названия которых включают комбинацию символов rc, за которыми сразу идет любая цифра. Для этого вводим в командную строку команду ls с опцией -l (подробный вывод, включающий помимо названий файлов данные об их размере, владельце и права доступа) и аргументом /etc. После чего с помощью конвейера | передаем результаты вывода команде grep rc[0-9]:
В данном примере регулярное выражение rc[0-9] как раз и означает, что команде grep нужно искать комбинацию символов rc с любой цифрой.
Учимся использовать команду cut
Еще одна важная команда, без которой нельзя получить сертификат LFCS — это команда cut.
Утилита cut — это программа для командной строки UNIX-подобных операционных систем, предназначенная для вырезания текста. С ее помощью пользователь может получить нужные ему части входных строк (как из текстового файла, так и из потока стандартного ввода stdin) и передать их в поток стандартного вывода stdout.
С командой cut можно использовать следующие опции:
-b— вырезать и вернуть заданное количество байтов;-c— вырезать и вернуть заданное количество символов;-f— вырезать и вернуть заданные поля;-d— заменить знак разделителя (по умолчанию разделителем считается табуляция).
Теперь давайте перейдем к практическому применению команды cut.
Вырезаем и форматируем текст с помощью команды cut
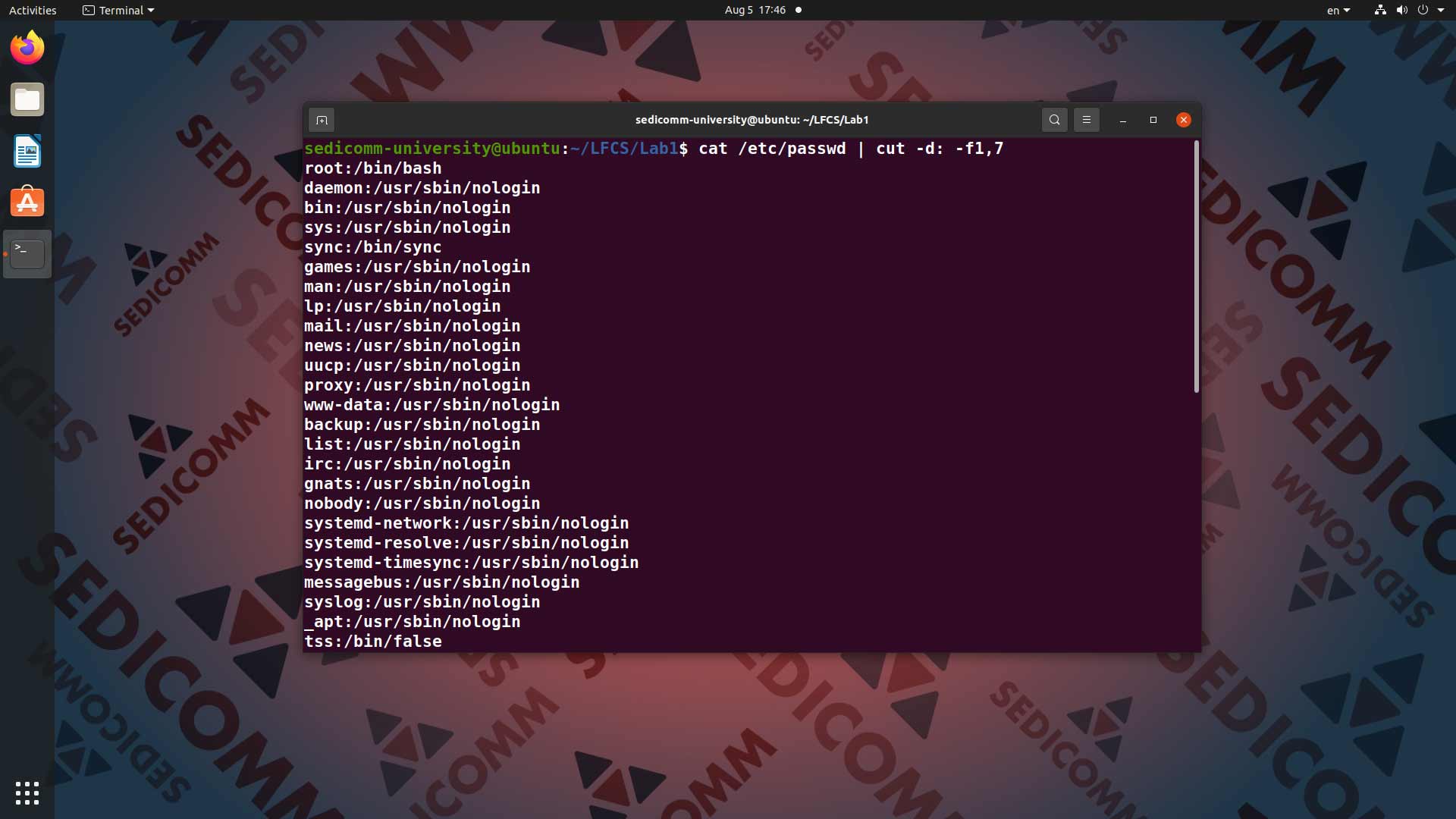
В рамках этого примера попробуем извлечь информацию из уже знакомого Вам файла /etc/passwd. Например — имена учетных записей пользователей и соответствующие им названия оболочек. По умолчанию этот файл содержит большой массив информации, который сложно читать. Чтоб вырезать и вывести на экран только искомую информацию — вводим в командную строку команду cat /etc/passwd и с помощью конвейера | передаем ее вывод команде cut -d: -f1,7:
В данном случае опция -d указывает, что как разделитель должно расцениваться двоеточие :. Тогда как с помощью опции -f команда будет вырезать и выводить на экран значения из полей №1 и №7.
Учимся использовать команды sort и uniq
Еще одна команда, без знакомства с которой не получится получить сертификат LFCS — это uniq.
Утилита uniq — это инструмент командной строки для семейства UNIX-подобных операционных систем, позволяющий удалять из текста повторяющиеся значения. По умолчанию команда uniq берет данные для обработки из потока стандартного ввода stdin (если не задан входной файл) и возвращает обработанный текст в поток стандартного вывода stdout (если не задан выходной файл).
Важно: команда uniq не распознает повторяющиеся строки, если они не следуют одна за другой — поэтому предварительно используется команда sort.
Утилита sort — это программа для командной строки семейства UNIX-подобных операционных систем, позволяющая выполнить сортировку текстовой информации (как в файле, так и в выводе другой команды).
Сортируем вывод с помощью команды sort
Прежде чем использовать команду uniq Вам так или иначе нужно будет сперва отсортировать текст. Для этого можно воспользоваться командой sort. В качестве первого примера возьмем результаты вывода команды du.
Утилита du (от англ. Disc Usage — использование диска) — это инструмент командной строки в ОС семейства GNU / Linux, предназначенный для мониторинга объема использования дискового пространства различными каталогами.
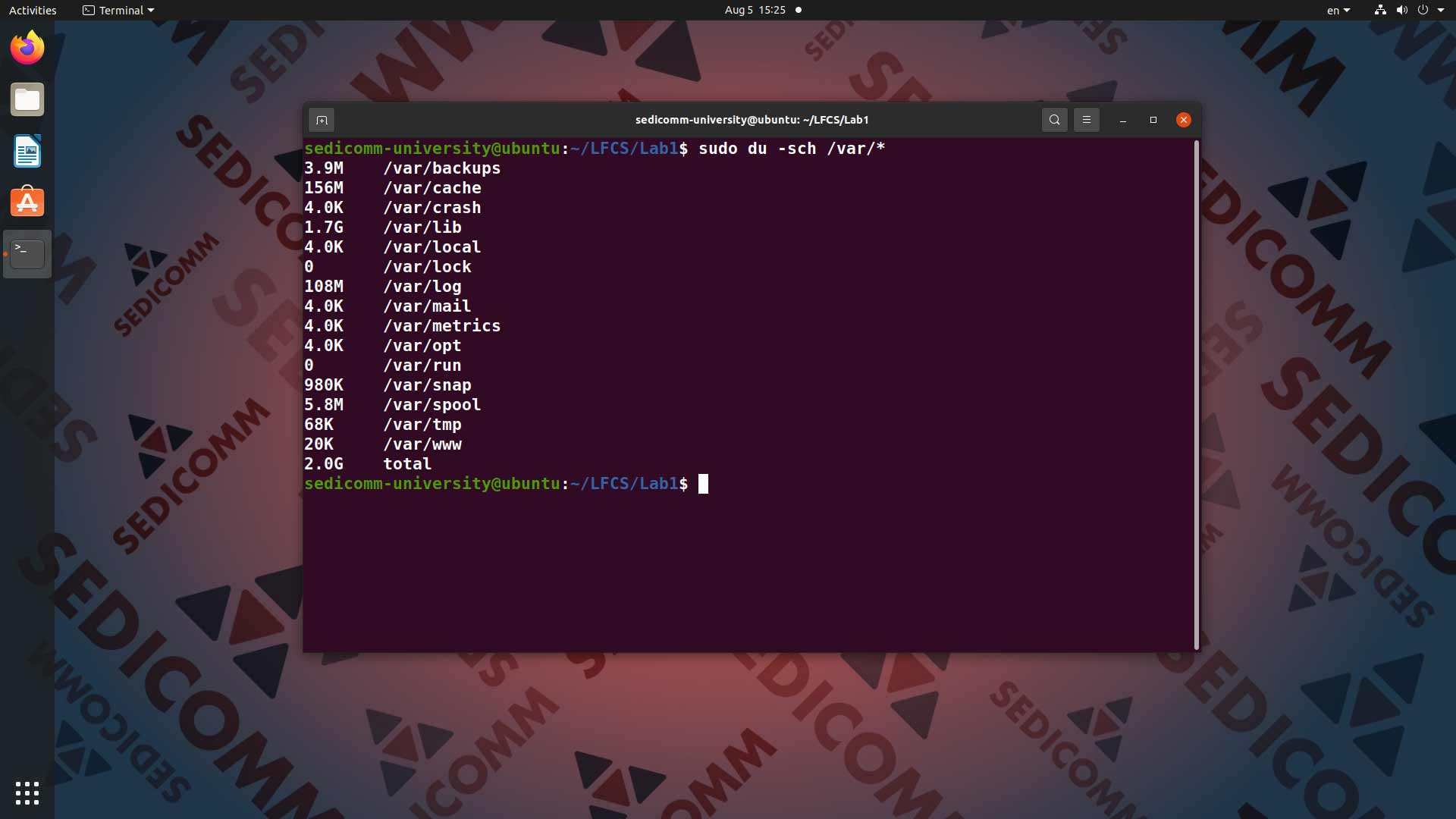
Давайте попробуем проверить, сколько дискового пространства используют различные подкаталоги в каталоге /var. Для этого вводим в командную строку команду sudo du -sch /var/*:
Важно: в данном случае команде du нужно предоставить права суперпользователя с помощью команды sudo (иначе операционная система не предоставит доступ к данным о каталоге /var).
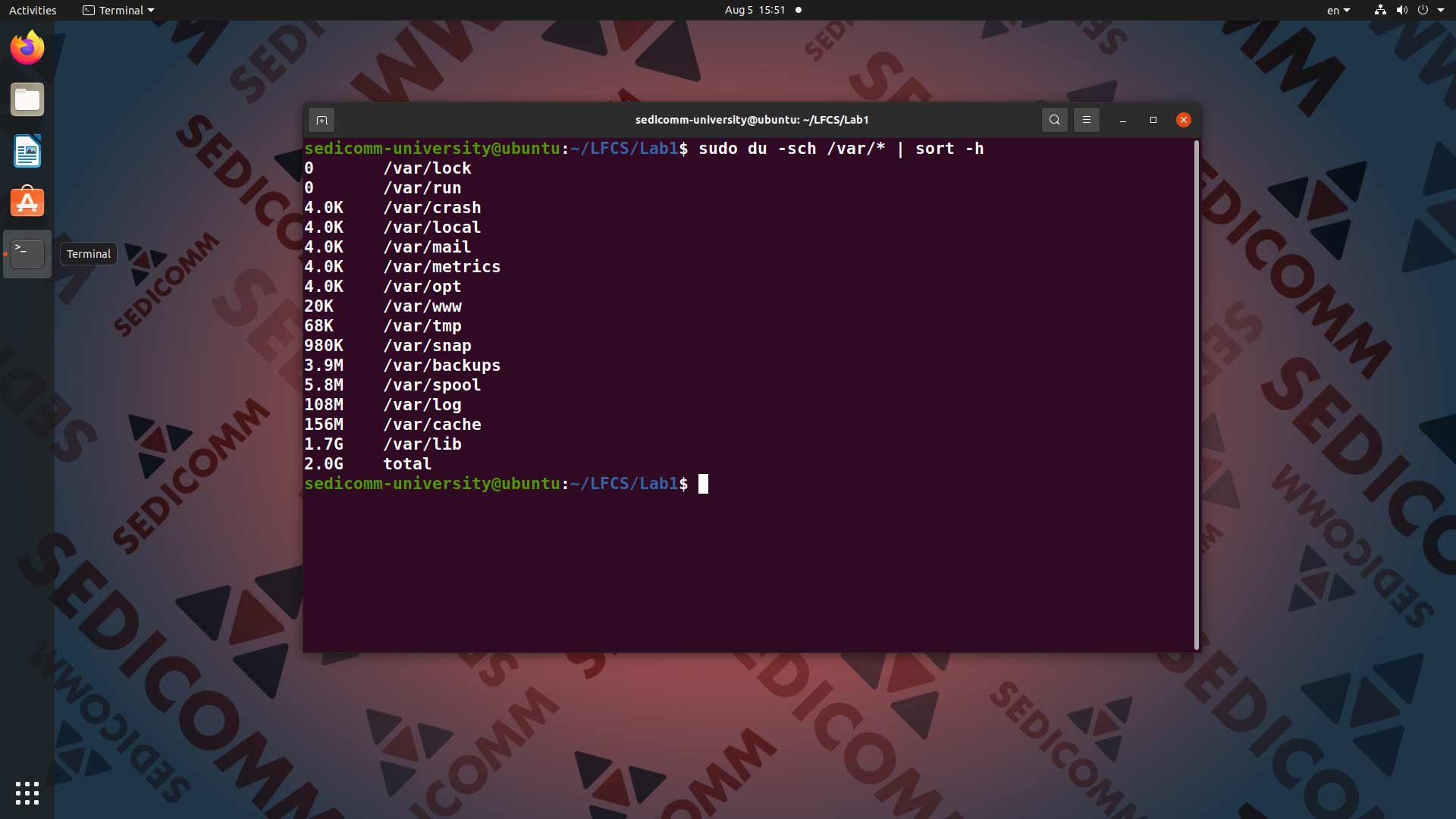
По умолчанию результаты вывода команды du сортируются только по названию подкаталога (а не по размеру). Однако с помощью команды sort это можно легко исправить. Для этого дополняем нашу команду sudo du -sch /var/* с помощью конвейера | командой sort -h:
В результате строки отсортированы по возрастанию занимаемого подкаталогом дискового пространства.
Подсчитываем количество событий за день в файле журнала с помощью команды uniq
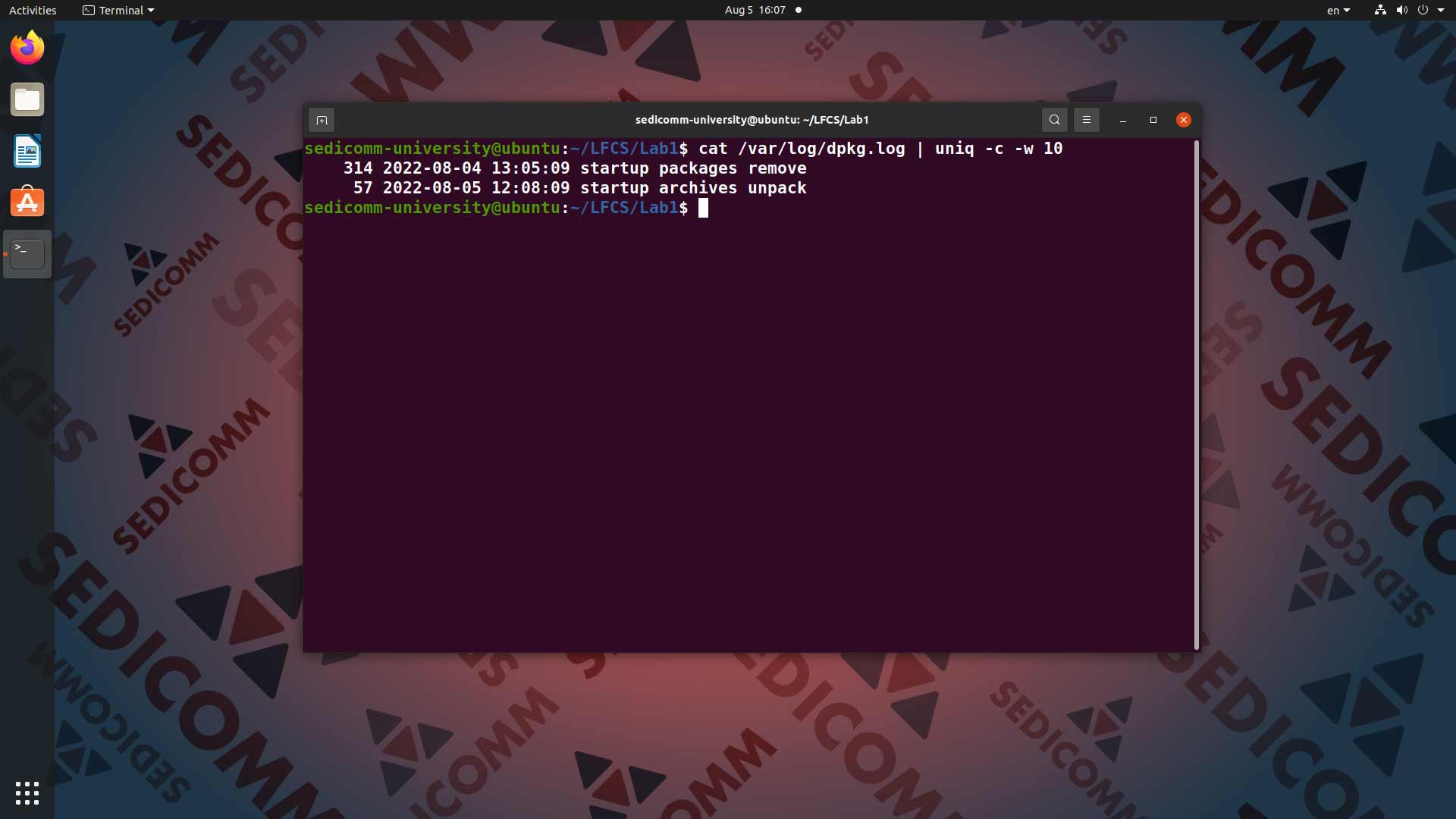
Системному администратору Linux нужно отслеживать по файлам журналов (логов) множество различных событий. Даже количество событий, зафиксированных за день, может многое сказать о том, нормально ли работает операционная система. В уже знакомом Вам файле /var/log/dpkg.log дата занимает первые 10 символов каждой строки.
С помощью команды uniq можно не только удалить все строки, у которых повторяется те самые первые 10 символов, содержащие дату. Но и получить информацию о том, сколько раз каждое уникальное значение даты повторяется. То есть, сколько записей в тексте файла журнала имеют одинаковую дату. Для этого вводим в командную строку команду cat /var/log/dpkg.log (вывод на экран содержимого файла) и с помощью знака конвейера | добавляем передаем результат команде uniq -c -w 10:
Давайте разберемся в том, что в данном примере означают опции команды uniq:
-c— вывод перед каждой строкой количества повторений через пробел;-w— число символов строки, участвующих в операции сравнения.
В результате изменяя значение опции -w Вы можете легко подсчитать число событий за каждый день в любом файле журнала.
Объединяем возможности команд sort и uniq
Команды sort и uniq можно очень удобно объединять. Допустим, что у Вас есть текстовый файл sortuniq.txt, содержащий следующие данные о тратах членов коллектива:
- имя сотрудника;
- дату;
- сумму.
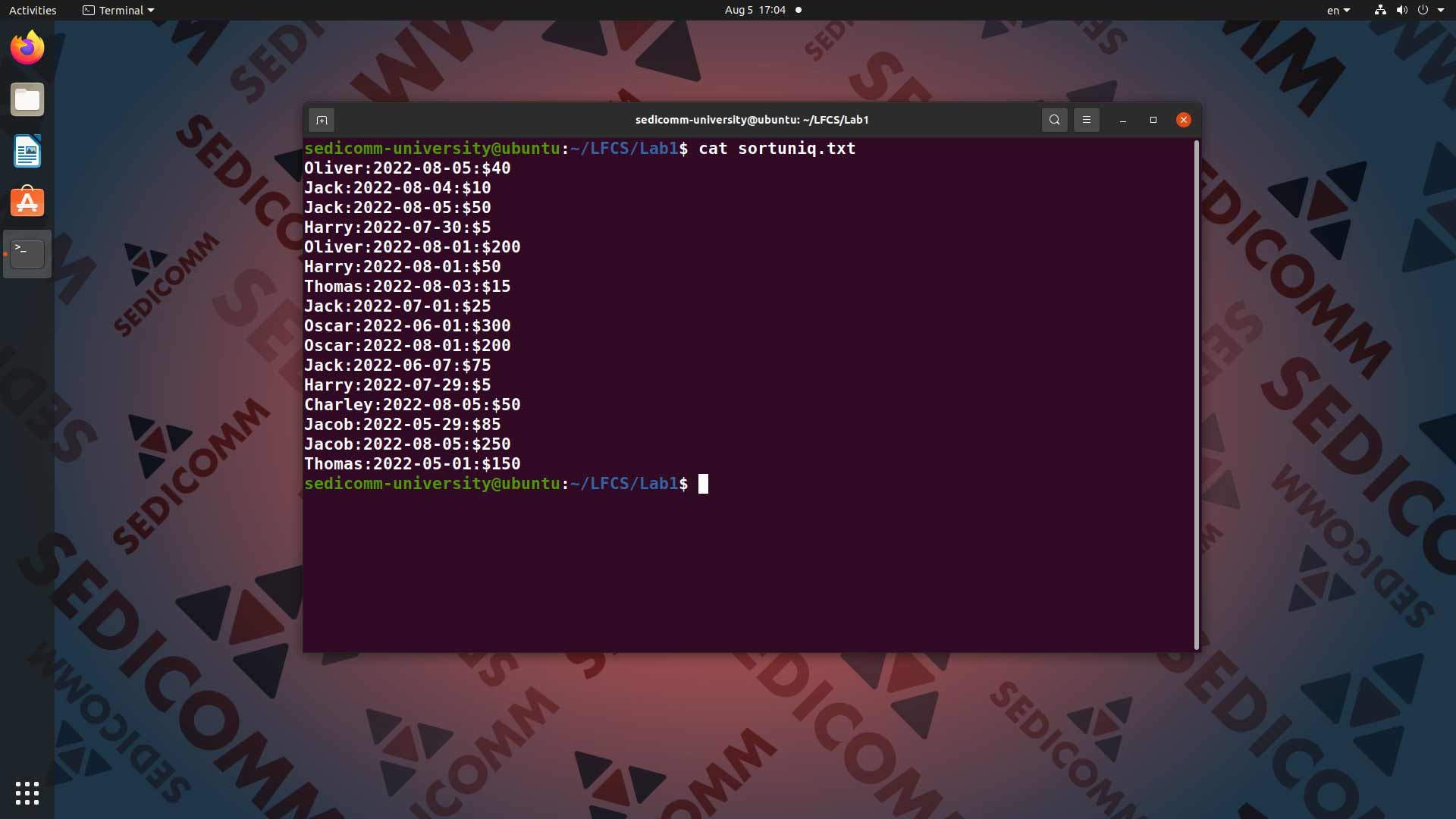
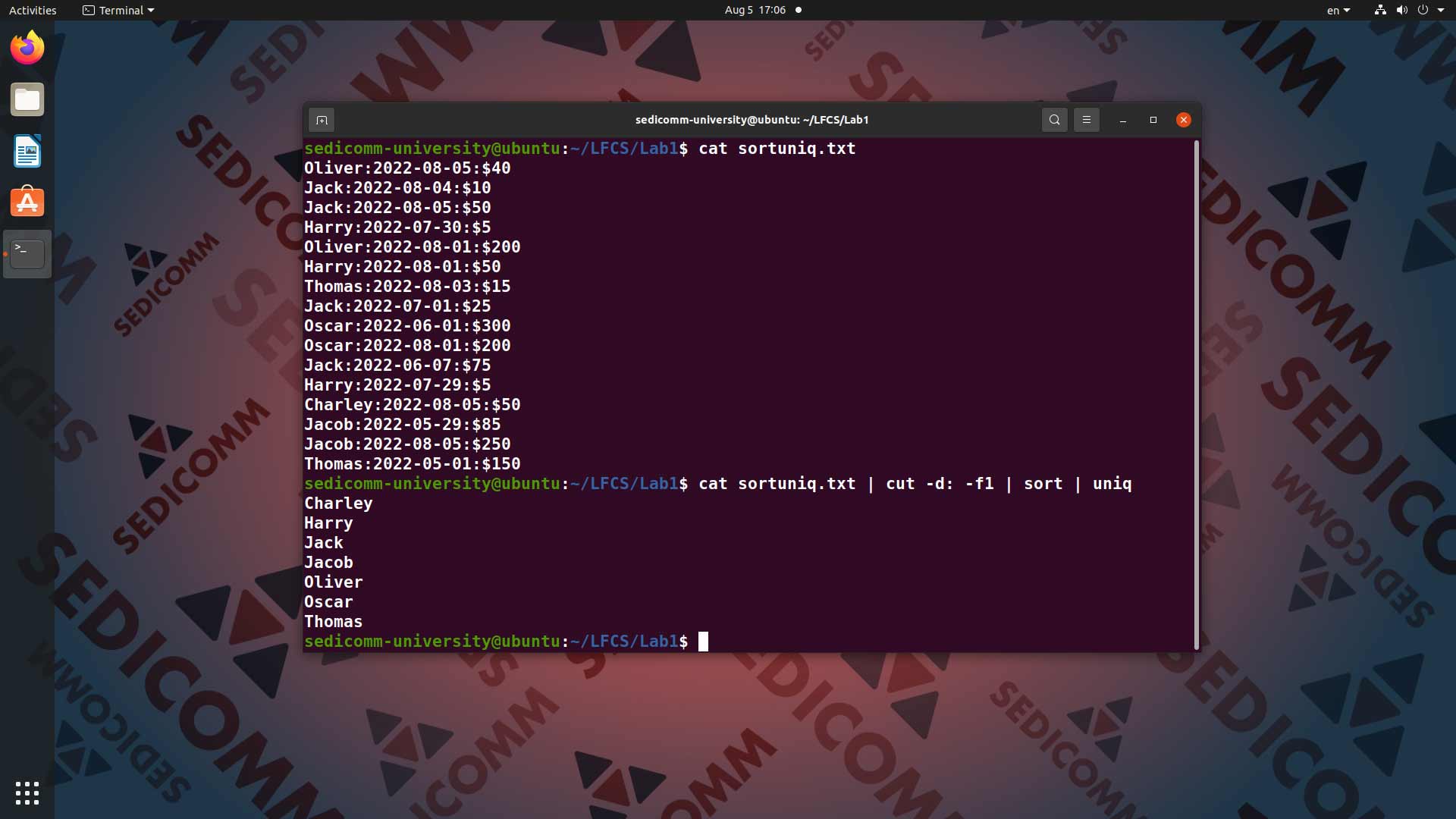
Предположим, что Вам нужно вывести на экран список всех членов коллектива без повторений. Для этого вводим в командную строку команду cat sortuniq.txt, ее вывод с помощью конвейера | передаем команде cut -d: -f1, после чего еще раз с помощью конвейера | передаем вывод команде sort, после чего еще раз с помощью конвейера | передаем вывод команде uniq:
Учимся использовать команду tr
Последняя команда, о которой Вы узнаете в рамках этого урока — tr. И умение ее использовать также обязательно пригодится Вам на экзамене LFCS.
Утилита tr (от англ. translate) — это простой инструмент командной строки Linux, предназначенный для замены символов или удаления из текста. От более сложных аналогов программа отличается полным отсутствием поддержки работы с файлами напрямую. То есть, с помощью команды tr можно изменять только те текстовые данные, которые:
- получены напрямую из стандартного ввода (поток 0 —
stdin); - перенаправлены из стандартного вывода (поток 1 — stdout) другой команды.
Теперь давайте попробуем разобраться в возможностях команды tr и в том, как с ее помощью выполняется обработка текстовых потоков в Linux.
Переводим символы из нижнего регистра в верхний с помощью команды tr
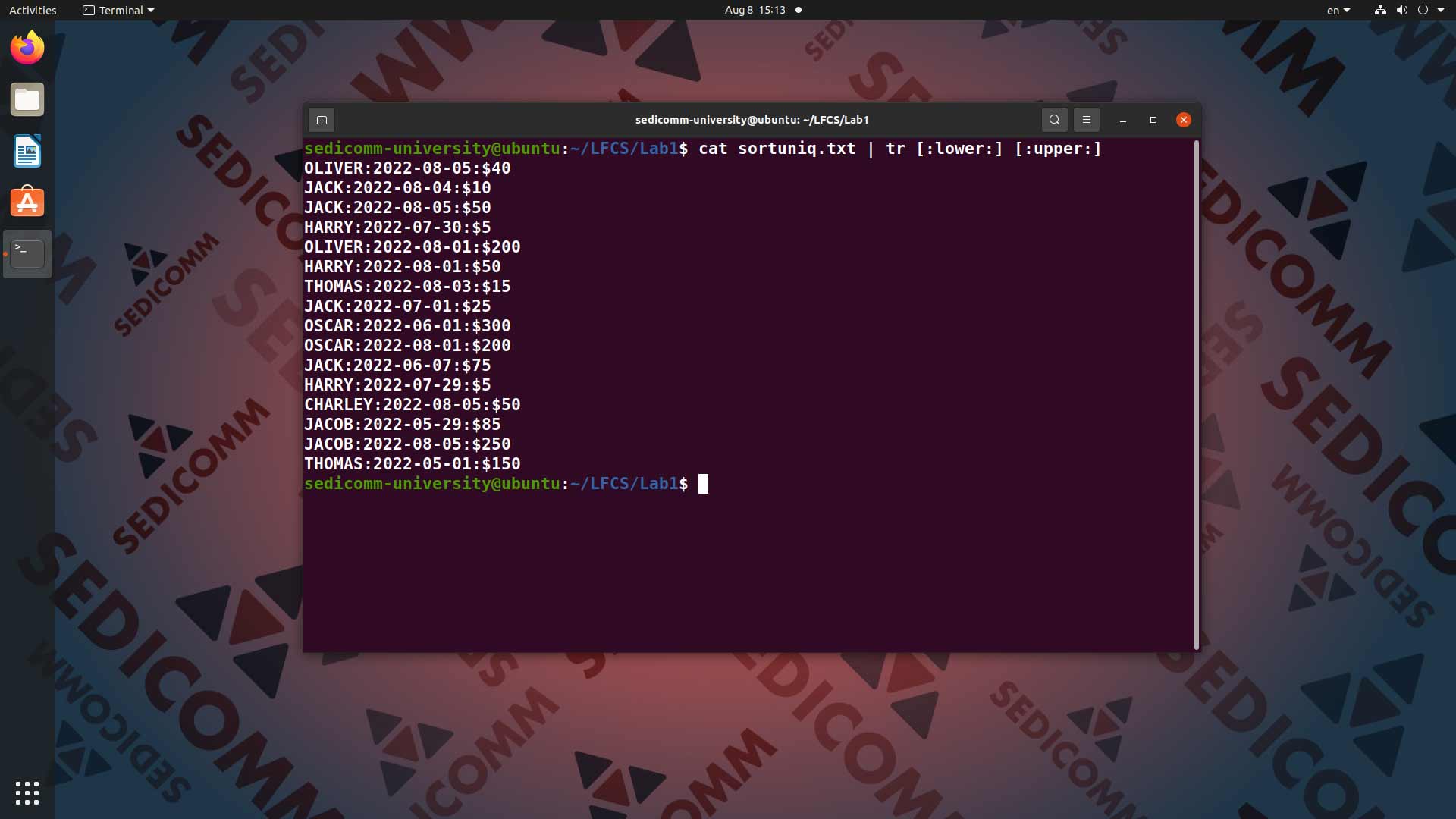
Попробуем перевести все символы в файле sortuniq.txt из нижнего в верхний регистр (то есть сделать из строчных букв прописные). Для этого вводим в командную строку команду cat sortuniq.txt и передаем ее вывод с помощью конвейера | команде tr [:lower:] [:upper:]:
Заменяем разделитель в тексте с помощью команды tr
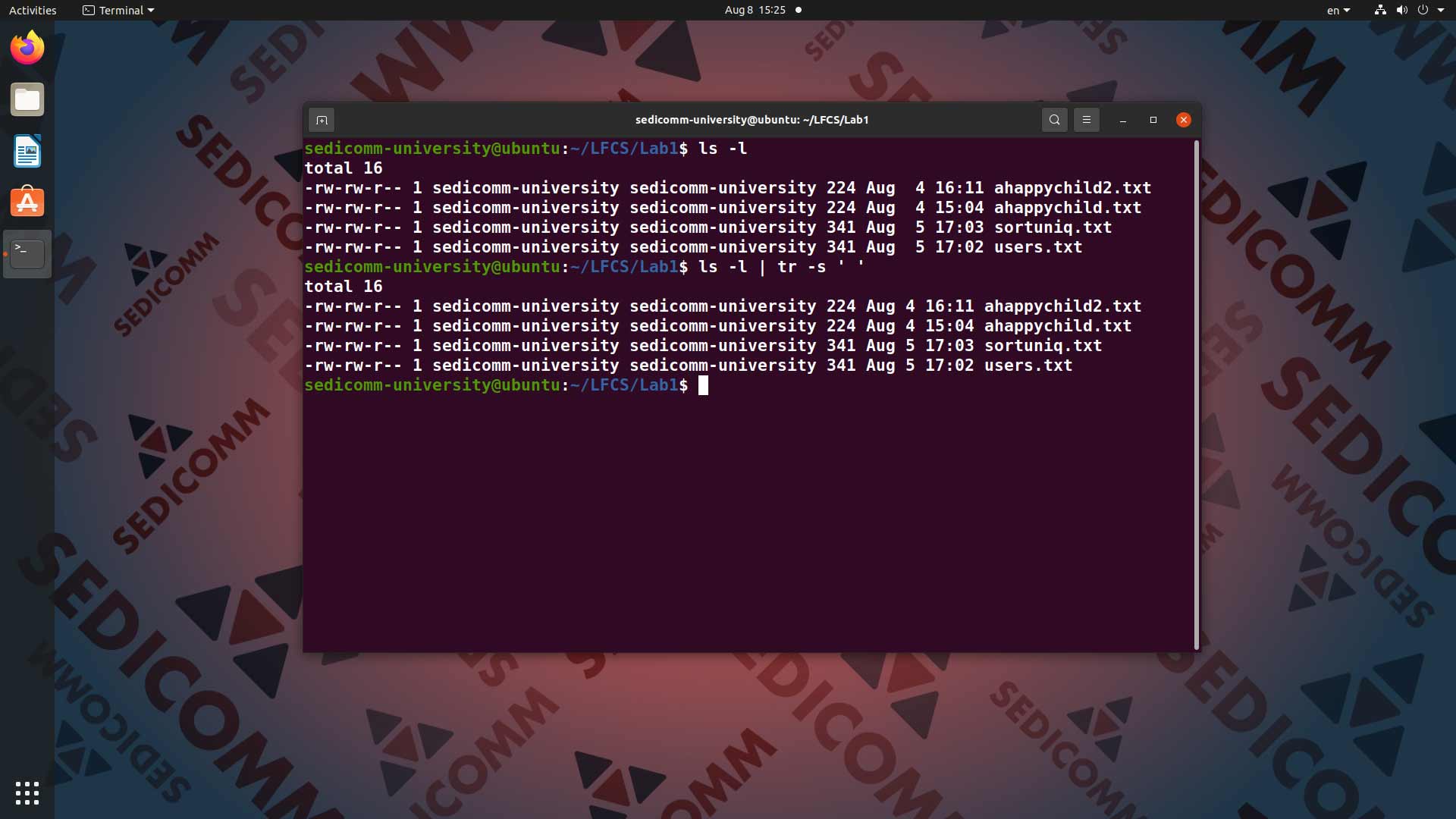
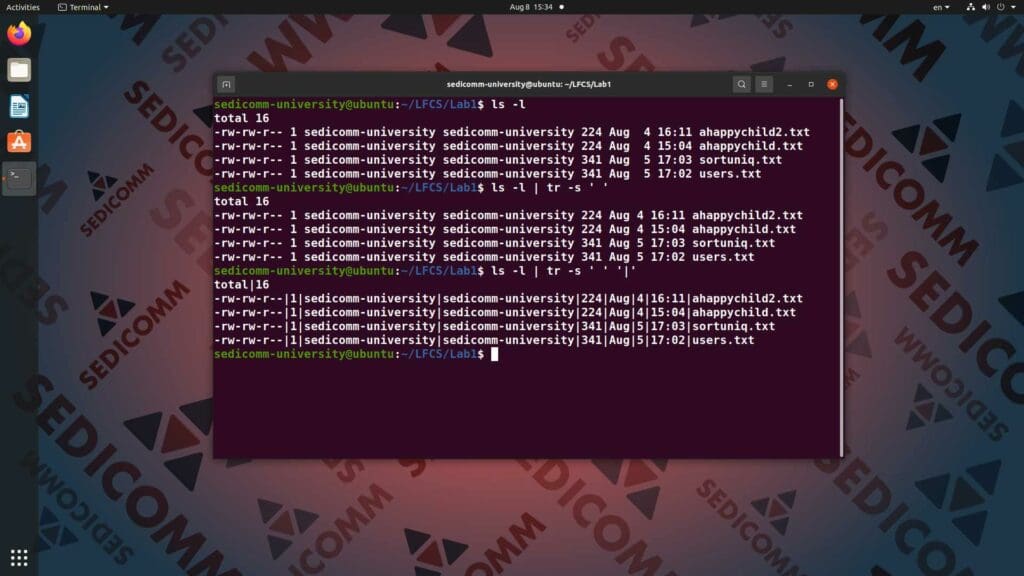
Самым частым способом использования команды tr в Вашей практике будет замена разделителя в тексте. Например — двойного пробела в выводе. Прежде всего, вводим в командную строку команду ls -l:
Далее снова вводим в командную строку команду ls -l и с помощью конвейера | передаем ее вывод команде tr -s ' ':
Поскольку мы задали только первый набор символов для замены и не задали второй — команда tr просто осуществила замену повторяющихся пробелов.
Однако в данном случае замена не выглядит достаточно очевидной. Поэтому давайте попробуем вместо пробела использовать в качестве разделителя вертикальную черту. Для этого вводим в командную строку ls -l и с помощью конвейера | передаем ее вывод команде tr -s ' ' '|':
В данном случае команда tr находит в выводе команды ls -l пробел из первого набора символов (' ') и заменяет символом их вертикальной чертой из второго набора ('|'). Попробуйте самостоятельно выбрать другие символы для замены, чтобы посмотреть на результат работы команды tr.
Выводы
Вы прошли первый урок в рамках подготовки к сертификации LFCS, узнали о том, как выполняется обработка текстовых потоков в Linux. А также познакомились с командами sed, grep, cut, sort, uniq и tr, которые в различных комбинациях помогут Вам решать целый спектр задач начинающего системного администратора. С их помощью Вы можете собирать, фильтровать, форматировать, комбинировать и перенаправлять (как в качестве ввода команды, так и в файл) различную полезную информацию из стандартного вывода.
Спасибо за время, уделенное прочтению статьи! Полный список уроков для прохождения индустриальной сертификации: Курс LFCS (Linux Foundation Certified Sysadmin): программа подготовки к экзаменам.
Если возникли вопросы — задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!
Чтобы знать больше и выделяться знаниями среди толпы IT-шников, записывайтесь на курсы Cisco, курсы по кибербезопасности, полный курс по кибербезопасности, курсы DevNet / DevOps (программируемые системы) от Академии Cisco, курсы Linux от Linux Professional Institute на платформе SEDICOMM University (Университет СЭДИКОММ).
Курсы Cisco, Linux, кибербезопасность, DevOps / DevNet, Python с трудоустройством!
- Поможем стать экспертом по сетевой инженерии, кибербезопасности, программируемым сетям и системам и получить международные сертификаты Cisco, Linux LPI, Python Institute.
- Предлагаем проверенную программу с лучшими учебниками от экспертов из Cisco Networking Academy, Linux Professional Institute и Python Institute, помощь сертифицированных инструкторов и личного куратора.
- Поможем с трудоустройством и стартом карьеры в сфере IT — 100% наших выпускников трудоустраиваются.
- Проведем вечерние онлайн-лекции на нашей платформе.
- Согласуем с вами удобное время для практик.
- Если хотите индивидуальный график — обсудим и реализуем.
- Личный куратор будет на связи, чтобы ответить на вопросы, проконсультировать и мотивировать придерживаться сроков сдачи экзаменов.
- Всем, кто боится потерять мотивацию и не закончить обучение, предложим общение с профессиональным коучем.
- отредактировать или создать с нуля резюме;
- подготовиться к техническим интервью;
- подготовиться к конкурсу на понравившуюся вакансию;
- устроиться на работу в Cisco по специальной программе. Наши студенты, которые уже работают там: жмите на #НашиВCisco Вконтакте, #НашиВCisco Facebook.



















