

Скриптовый язык AWK — это мощный инструмент командной строки, предназначенный для обработки текста. Он позволяет быстро и эффективно выполнять различные манипуляции с данными в файле. Начинающим пользователям AWK может показаться сложным языком. Но для тех, кто не полениться приложить немного усилий, он может стать незаменимым инструментом при решении широкого спектра задач.
В этой статье мы рассмотрим основные принципы языка сценариев AWK и покажем 33 примера использования, начиная с простых и заканчивая более сложными задачами.
Содержание:
- Как AWK обрабатывает текст
- Как использовать язык сценариев AWK
- Выводы
Как AWK обрабатывает текст
Прежде чем перейти к практической части, давайте разберем как AWK работает с содержимым документа. Скриптовый язык при обработке строк текста разбивает каждую из них на поля. По умолчанию разделителем полей является пробел или табуляция, но этот разделитель может быть изменен пользователем. Обращение к полям осуществляется с помощью переменных $1, $2, $3, которые соответствуют первому, второму, третьему и т. д. полям текущей строки.
Например, если у нас есть строка Sedicomm is the best university, то $1 будет содержать слово Sedicomm, $2 — is, $3 — the и т. п. Поля могут использоваться для выполнения различных операций, таких как сравнение, изменение и объединение содержимого файла.
Встроенные переменные AWK
Язык сценариев поддерживает множество встроенных переменных, а также позволяет создавать пользовательские. Эти переменные могут использоваться в скриптах AWK без объявления и применяться для хранения информации о текущем поле, количестве обработанных строк и других данных.
Рассмотрим несколько наиболее часто используемых встроенных переменных AWK:
FS— разделитель полей (по умолчанию — пробел или табуляция);OFS— разделитель вывода (по умолчанию — пробел);RS— разделитель записей (по умолчанию — символ новой строки);ORS— разделитель вывода записей (по умолчанию — символ новой строки);NF— указывает количество полей в текущей записи;NR— представляет номер текущей обрабатываемой строки;$0— указывает содержимое текущей записи целиком;$1,$2,$3, … — содержимое первого, второго, третьего и т.д. полей в текущей записи.
Эти переменные мы и будем использовать для работы с языком AWK.
Как использовать язык сценариев AWK
Как мы уже говорили, AWK активно используется для обработки текстов. Поэтому, для демонстрации Вам его возможностей, создадим два файла с таблицами, которые содержат определенные неформатированные данные.

Первый файл:

И второй файл:

Важно: в обоих файлах есть пустые строки и лишние пробелы. Они будут использоваться для того, чтобы показать отдельные функции языка.
Вывод заданных строк файла
AWK позволяет отображать в терминале Linux заданные строки из файла. Для вывода определенных строк можно применять специальные фильтры или некоторые временные переменные, которые выбирают нужные строки по определенным критериям. Эта функция очень полезна при обработке файлов с большим количеством строк.
Вывод всех строк на экран
В операционной системе Linux существует большое количество команд или утилит, которые позволяют выводить все содержимое файла на экран. Данный скриптовой язык также предоставляет пользователям такую возможность. Для того, чтобы вывести все строки файла с помощью AWK, используйте следующую команду:

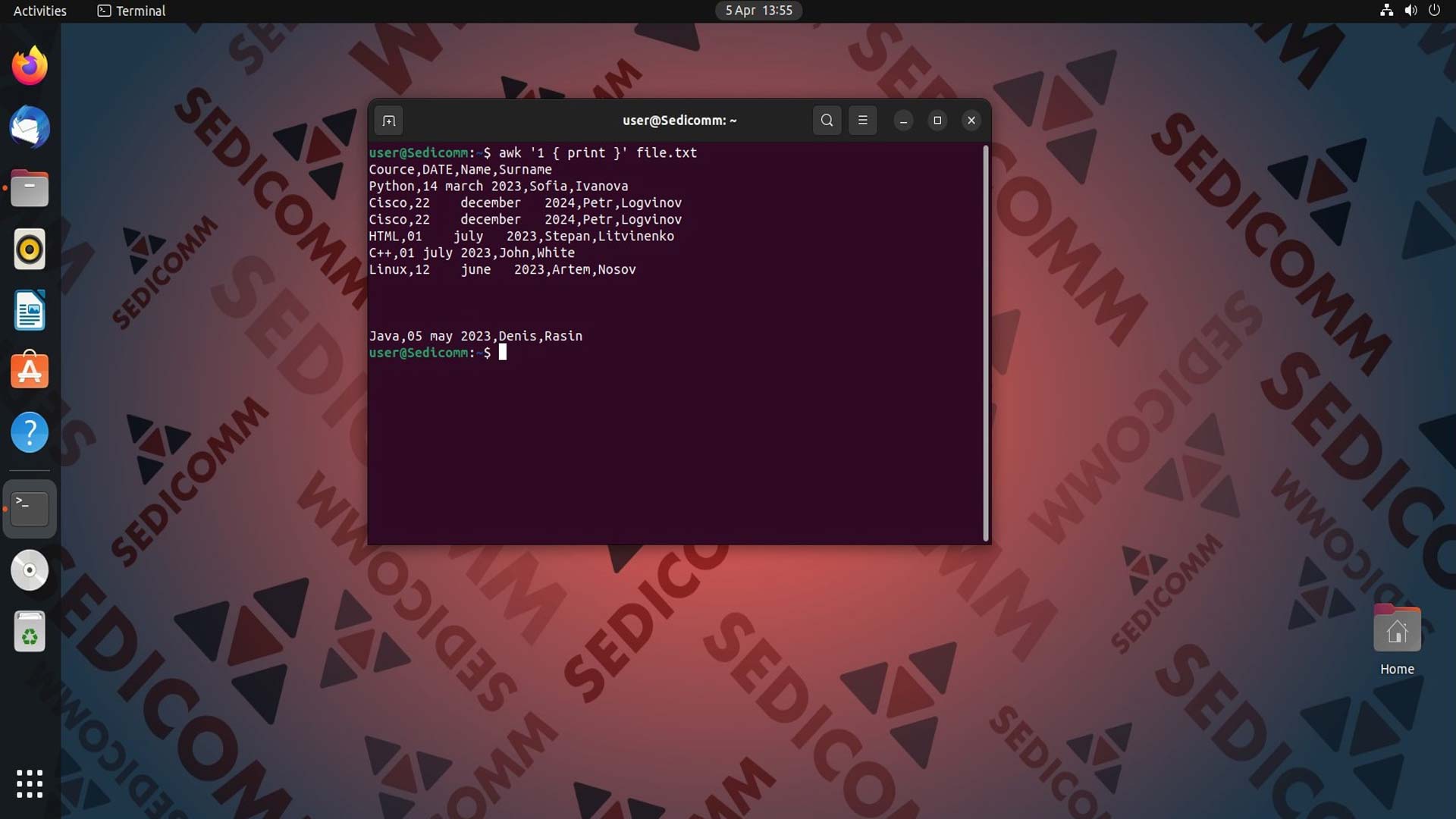
В AWK каждая строка файла воспринимается как запись. В этом случае, поскольку условие (шаблон) 1 соответствует истине (True) для каждой строки файла, то для каждой записи выполняется действие print, которое просто выводит эту строку на экран.
Блок { print } выполняется по умолчанию, поэтому его можно и не использовать для вывода всех строк файла:
Также можно и не определять условие 1 (True), тогда в таком случае, нужно вписать в команду блок { print } :
Если вместо 1 подставить 0 (False), что всегда является ложным, AWK не будет выполнять блок кода. В результате ничего не будет выведено на экран:
Вывод определенного диапазона строк
Чтобы ввести на экран строки из нужного Вам диапазона, используйте переменную NR, которая содержит номер текущей обрабатываемой строки.
Чтобы отобразить на экране все строки файла, кроме первой — выполните условие NR>1. Оно указывает, что выводить нужно только те строки, порядковый номер которых больше 1:

Чтобы вывести на экран текст, который находится между двумя определенными строками, выполните следующий код в терминале:

Показанный на скриншоте код возвращает строки из файла, которые находятся между второй и пятой строками, не включая их:
NR>2— условие, при котором AWK выбирает только строки, для которых номер строки больше 2, то есть все строки после второй;&&— логический оператор «И»;NR<5— условие, при котором AWK выбирает строки, для которых номер строки строго меньше 5.
Таким образом, команда выводит на экран строки с номерами 3 и 4.
Вывод всех строк, которые содержат хотя бы одно поле
Как было сказано ранее, наша таблица не отформатирована и содержит в себе пустые строки. Допустим, нам нужно отобразить только те строки, которые имеют хоть какую-то информацию. Чтобы это сделать, выполним команду:

В данном случае, если поле строки пустое, то условие возвращает логическое значение 0, и строка не выводится. Если поле не пустое, то условие возвращает 1, и строка выводится. Таким образом, указанная команда позволяет вывести все строки файла, которые содержат хотя бы одно заполненное поле.
Вывод всех строк, которые содержат хотя бы одно поле или только пробелы
В предыдущем примере, мы использовали код AWK для проверки наличия непустой строки (содержащей символы, отличные от пробелов и табуляций). Однако, в нашем файле есть та, которая содержит только пробелы. Чтобы вывести на экран ее вместе с остальными заполненными строками, введем в командной строке:

Извлечение столбцов из файла
Одним из основных преимуществ является возможность извлечения и обработки конкретных столбцов из файла. Для этой задачи используется переменная $n, где n — это номер столбца, который нужно извлечь. Например, $1:
Вывод на экран нескольких столбцов
Если необходимо извлечь сразу несколько столбцов из файла, их номера должны быть перечислены через запятую:

В этом примере:
FS=,— устанавливает разделителем полей запятую при считывании дынных из файла;OFS=,— устанавливает запятую как разделитель выведенных столбцов на экране;{ print $1, $3 }— указывает на то, что нужно вывести первое и третье поле из каждой строки файла.
Таким образом, после выполнения этой команды, в выводе останутся только первый и третий столбец исходного файла, разделенные запятой.
Важно: при использовании этого метода пустые строки также будут разделены запятыми.
Чтобы вывести на экран только непустые строки (также те, которые состоят только из пробелов), используйте команду:

Вывод на экран нескольких столбцов с помощью BEGIN
Вы также можете использовать блок BEGIN в команде для вывода нескольких столбцов файла. Модифицируем код из предыдущего примера следующим образом:

Ключевое слово BEGIN позволяет задать начальные условия для выполнения программы AWK перед тем, как начнется обработка входного файла. В данном случае, оно устанавливает значения для FS и OFS.
Математические операции в столбцах
Скриптовый язык AWK позволяет пользователям выполнять простые арифметические операции. Например, чтобы подсчитать сумму чисел первого столбца файла 1.txt, выполним одну из представленных команд:
Или:

При решении этой задачи нам потребовалась собственная переменная для хранения промежуточных значений SUM. Детальнее разберем конструкцию команды:
FS=, OFS=,— задает разделитель полей для входного и выходного файла как запятую;{ SUM=SUM+$1 }— поочередно перебирает каждую строку файла и прибавляет значение первого столбца к переменнойSUM;END { print SUM }— печатает значение переменнойSUM.
Таким образом, код вычисляет сумму первого столбца в файле и печатает ее на экран.
Подсчет количества непустых строк
Чтобы подсчитать количество строк в файле, которые содержат хотя бы один непробельный символ, можно использовать следующую конструкцию с ключевым словом END:
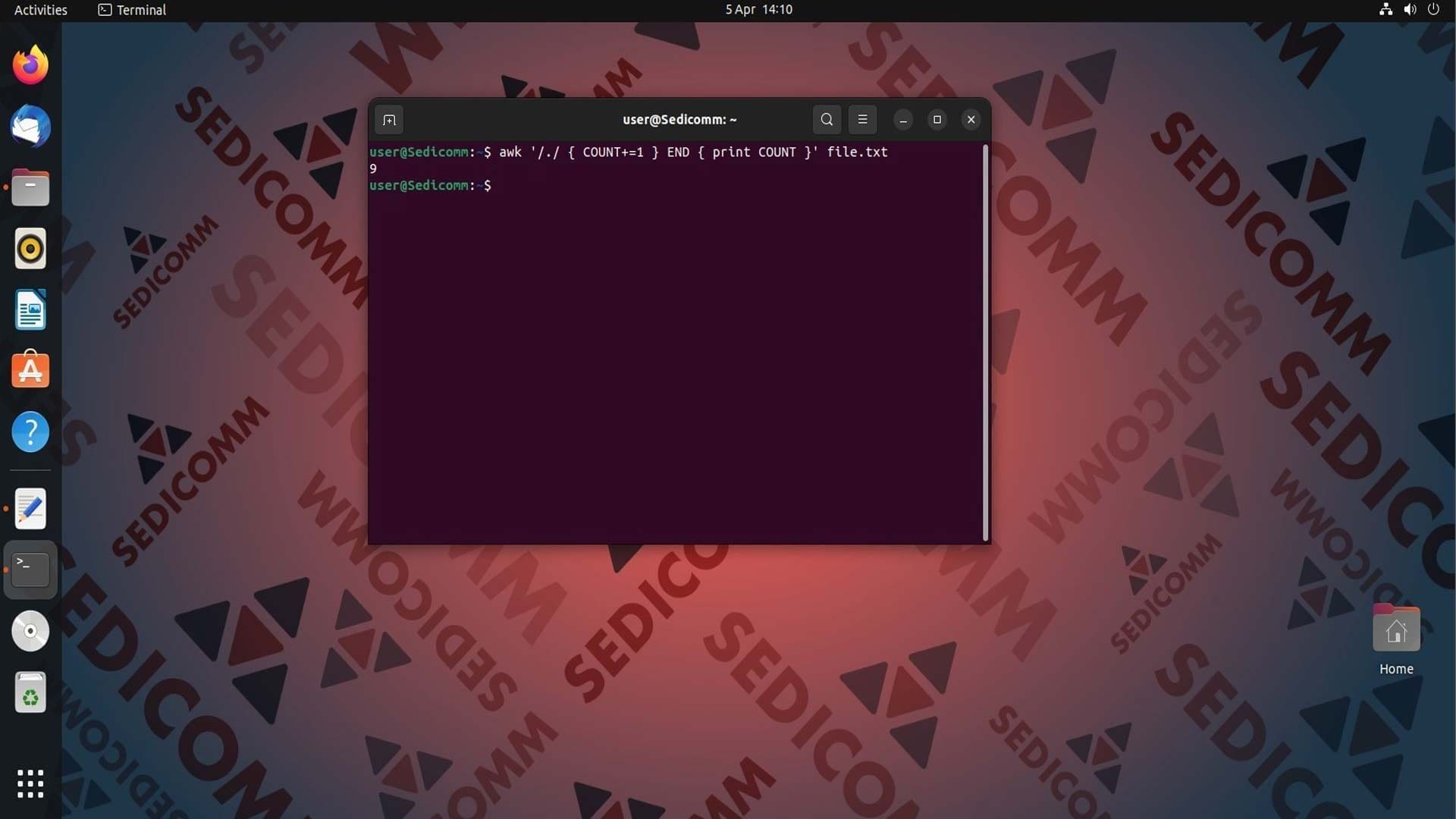
В этой конструкции содержатся несколько элементов, которые нужно объяснить:
/./— шаблон поиска, который соответствует любой строке, содержащей хотя бы один непробельный символ;{ COUNT+=1 }— выполняется для каждой строки и увеличивает значение переменнойCOUNTна единицу;END { print COUNT }— после обработки всех строк выводит значение переменнойCOUNT.
Чтобы вывести на экран число строк, которые содержат реальные данные (не пробелы или табуляции), введите в командной строке:
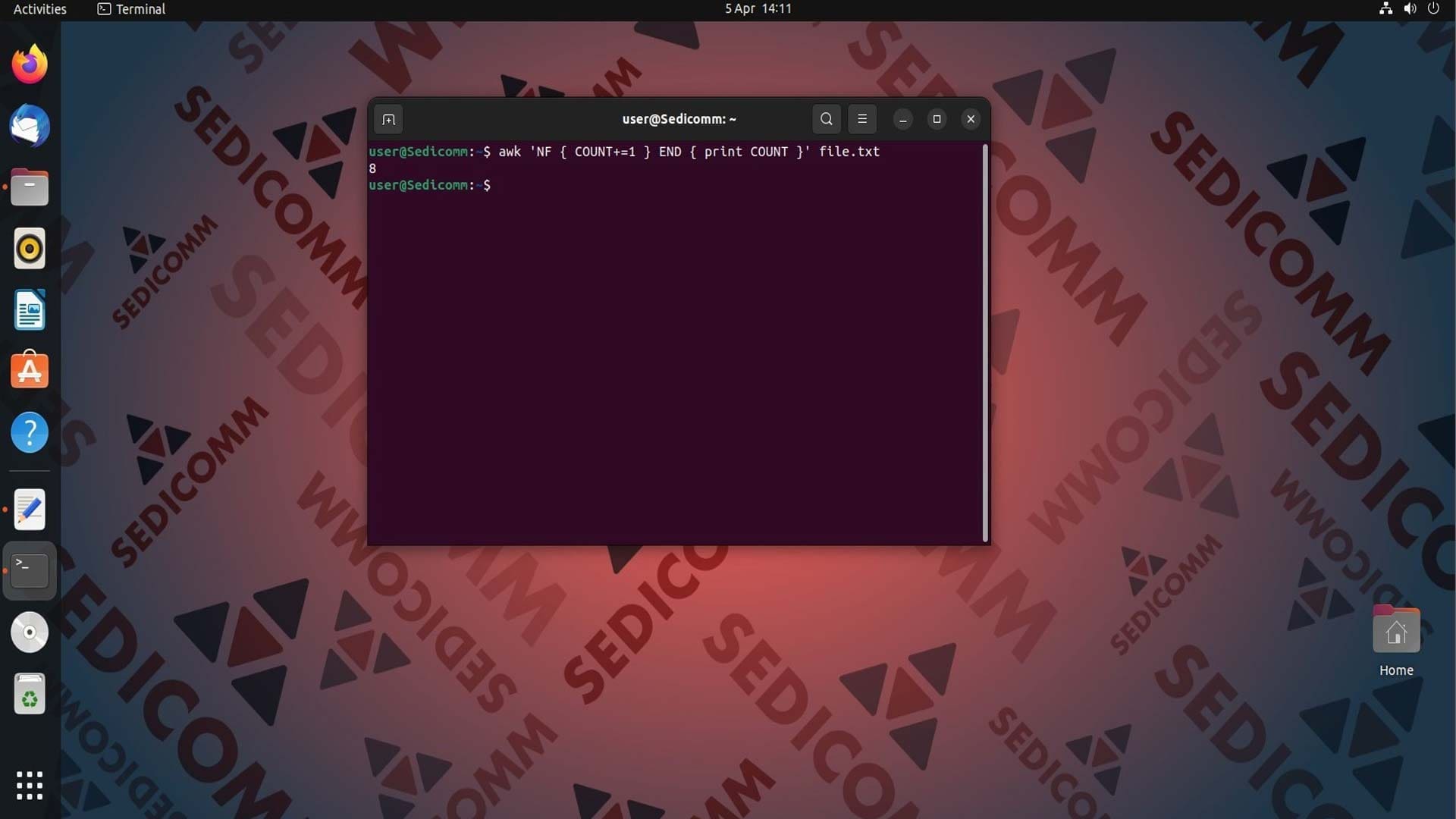
Здесь используется встроенная переменная NF, которая представляет количество полей в каждой строке файла. Если значение NF для строки не равно нулю (т.е. строка не пуста), то переменная COUNT увеличивается на 1. В конце обработки файла с помощью блока END скриптовый язык AWK выводит значение переменной COUNT, которая представляет собой количество строк, имеющих один или более символов.
Подсчет количества полей, которые содержат только числа
Поговорим о том, как определить какие данные содержат поля строки. Мы знаем, что в файле 1.txt первое поле каждой строки, кроме первой, имеет числовое значение. С помощью языка сценариев мы можем подсчитать их количество, выполнив команду:
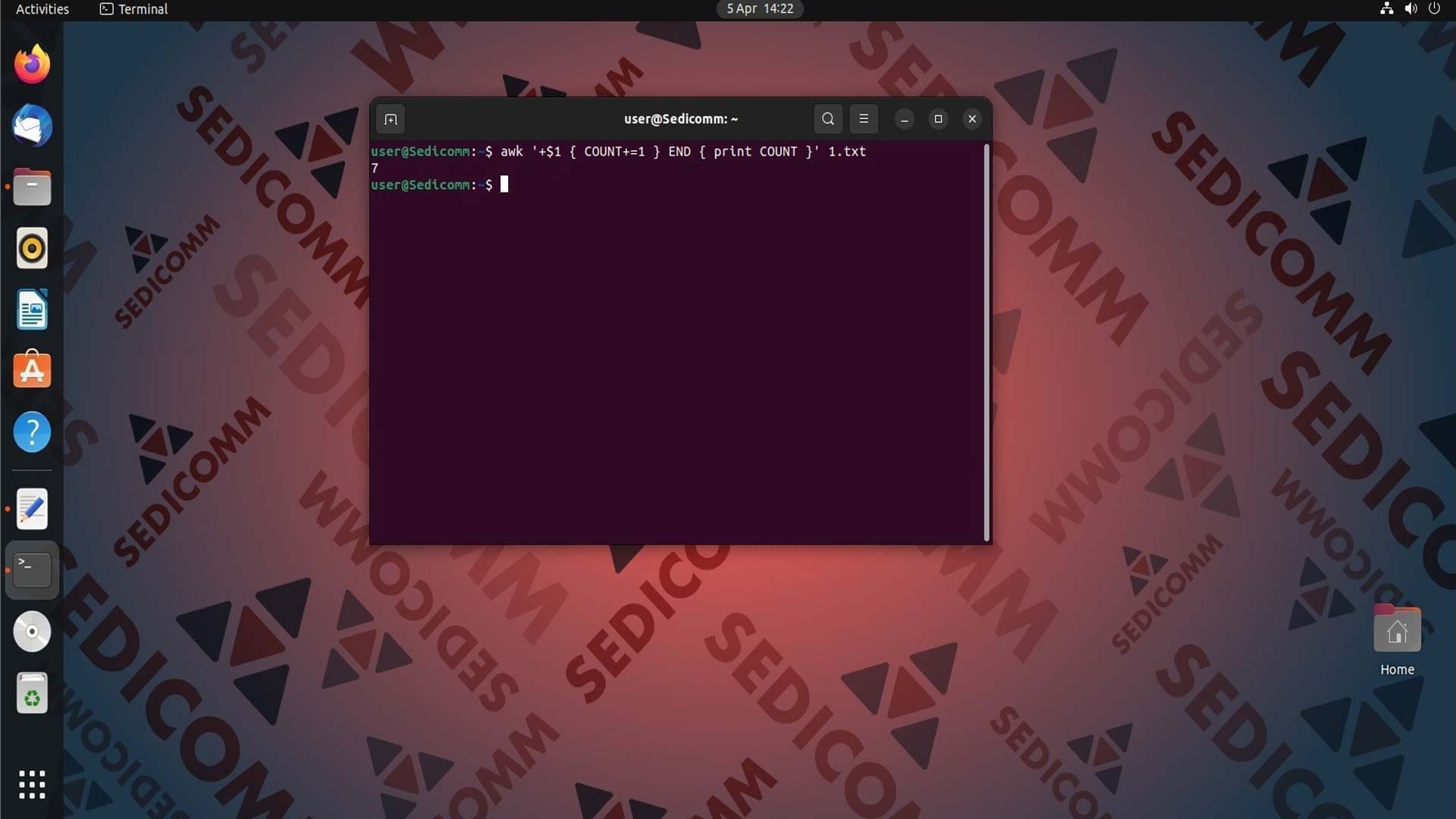
Подробнее разберем код:
+$1— проверяет, является ли значение первого поля в строке не равным нулю (также мы используем унарный плюс, чтобы преобразовать строку в число).{ COUNT+=1 }— увеличивает переменнуюCOUNTна единицу, если условие истинно.END { print COUNT }— выводит значение переменнойCOUNTна экран после обработки всего файла.
Использование массивов в AWK
Язык AWK имеет встроенную поддержку массивов, что делает его мощным инструментом для анализа структурированных данных. Массивы в AWK — ассоциативные, то есть они используются для хранения пар «ключ-значение». Ключ может быть любой строкой, а значение — любым типом данных, включая другой массив. Для доступа к элементам массива используется имя массива и ключ в квадратных скобках.
Сопоставление данных из двух столбцов
Рассмотри на примере. В файле 1.txt в первом столбце хранятся числа, а в третьем имена людей. Допустим, нам нужно вывести на экран два столбца (первый и третий). Однако, одно из имен (Petr) повторяется в таблице, то есть ему соответствует сразу два числа. В таком случае, при сопоставлении эти два числа суммируются:
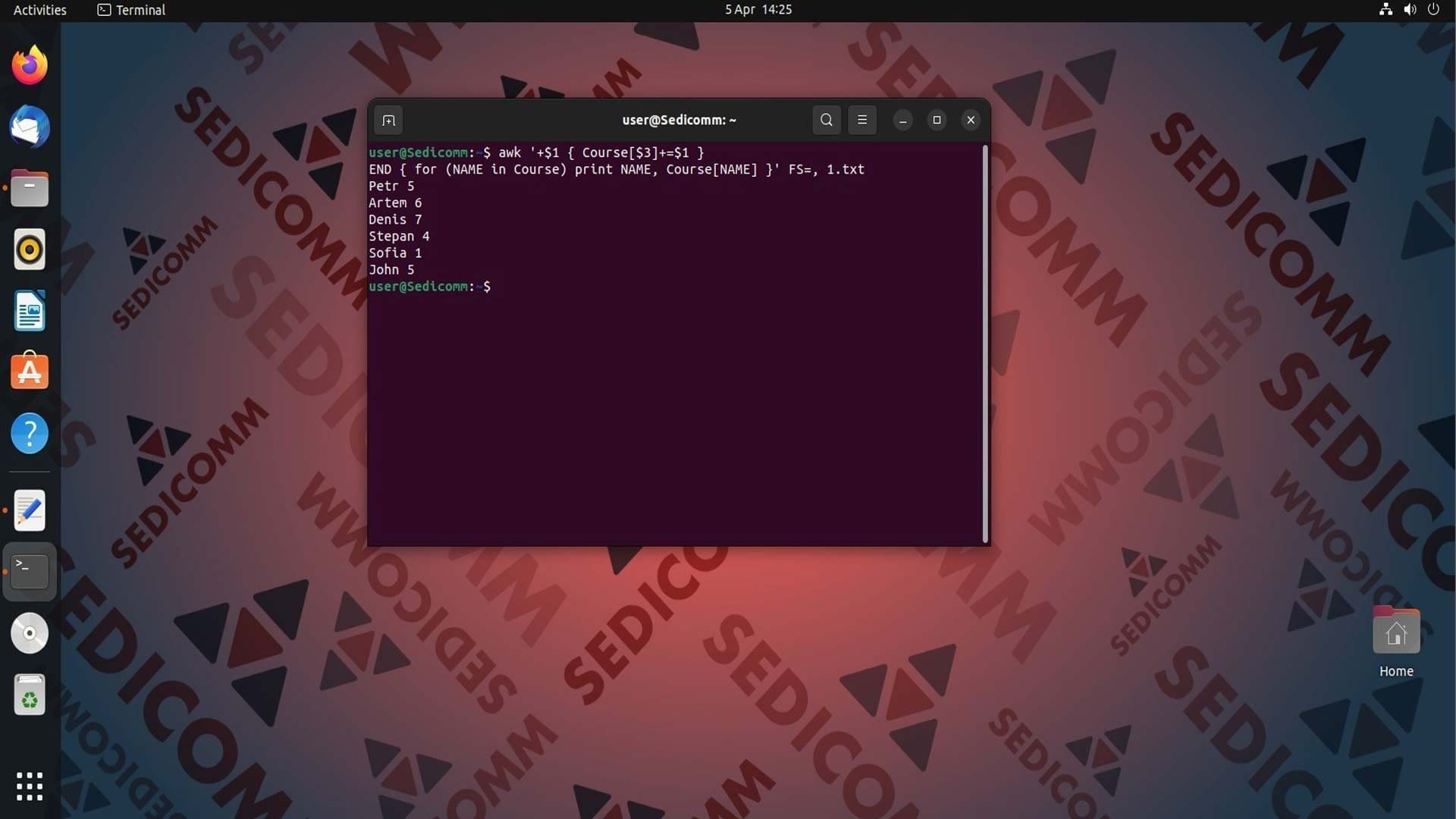
Действия, которые выполнила команда:
- Для каждой строки файла, содержащей число в первом столбце, добавляется значение этого числа к элементу массива
Course, который использует третий столбец (имена) в качестве индекса. - Блок
ENDобрабатывает все элементы массиваCourseи выводит их на экран, используя циклfor. Для каждого элемента функцияprintвыводит соответствующее имя (индекс массива) и сумму чисел. - Опция
FS=,задает запятую в качестве разделителя полей.
Важно: если в файле содержатся строки без положительных чисел в первом столбце, они будут проигнорированы.
Определение повторяющихся строк с использованием AWK
В таблице могут содержаться повторяющиеся строки. И в большом файле довольно сложно отыскать их самостоятельно. Однако, использование массивов поможет легко автоматизировать этот процесс:

Этот код отображает только уникальные строки в файле. Когда AWK читает строки, они сохраняются в массиве a. Если AWK встречает строку, которая уже есть в массиве a, он ее игнорирует. Если же встречает новую строку — добавляет ее в массив a с помощью оператора ++. В результате на экран выводятся строки, которые встретились более одного раза.
Игнорирование повторяющихся строк
Данная задача противоположна предыдущей. Однако, в данном случае, выводятся строки без повторов. Если строка имеет дубликат — он игнорируется, а оригинальная запись записывается в стандартном выводе. Например:
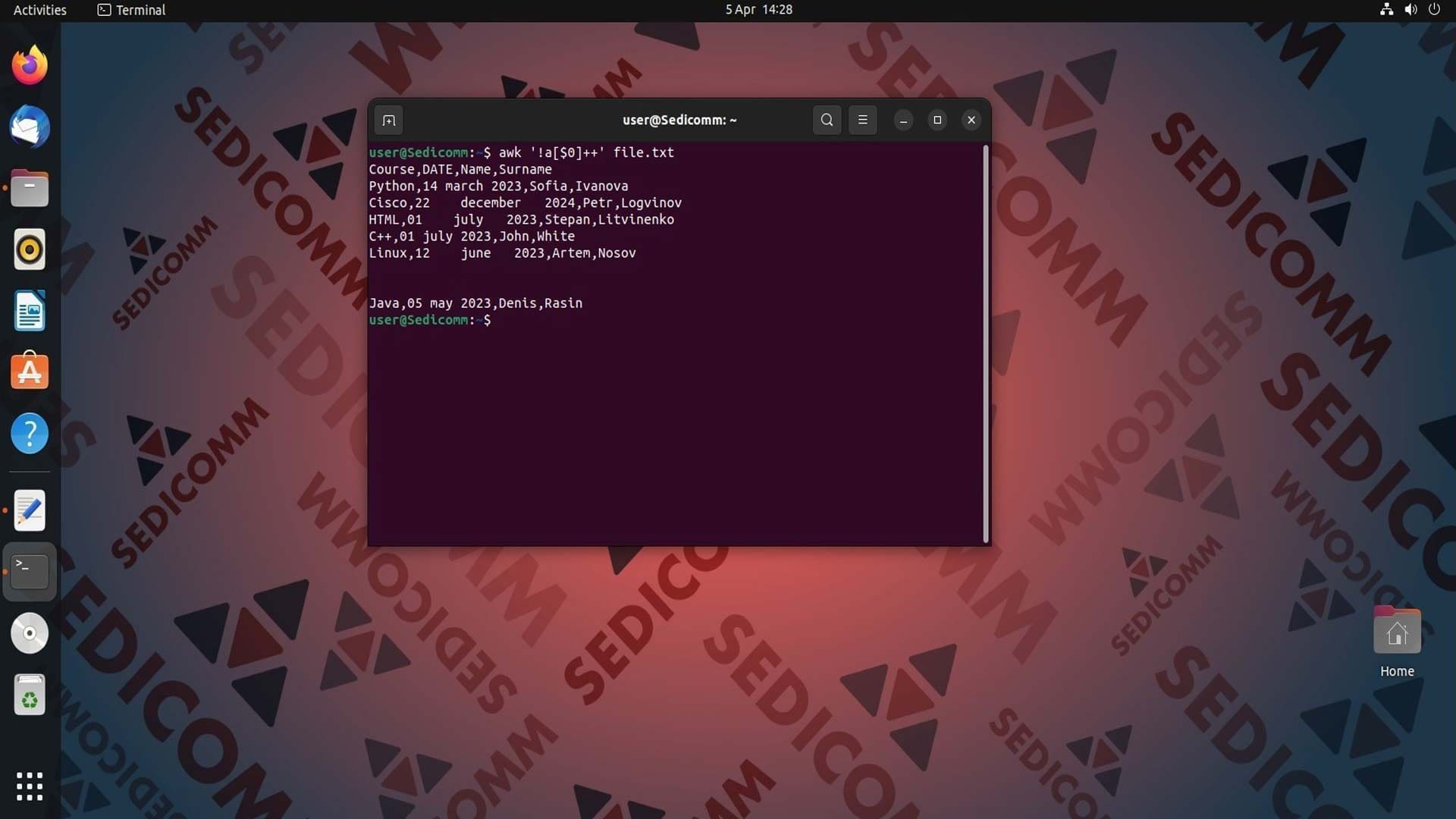
Использование временных переменных FS и OFS
В AWK встроены две переменные: FS и OFS, которые используются для указания разделителя полей между столбцами во входных и выходных данных, соответственно. Скриптовый язык позволяет задавать им собственные значения, чтобы изменить вид содержимого при выводе на экран.
Изменение разделителей полей
Как Вы знаете, все поля в нашей исходной таблице разделены пробелами. Допустим, мы хотим заменить пробелы на точку запятой. Для этого будем использовать следующую команду:

Здесь:
FS=,— задает символ запятой в качестве разделителя полей входного файла.OFS=';'— задает символ точки с запятой в качестве разделителя полей выходного файла.- Операция
$1=$1присваивает первому полю в строке его же значение, таким образом происходит переформатирование строки. Как результат, пробелы и табуляции между полями удаляются.
В результате, каждая строка будет выведена с новым разделителем полей, заданным переменной OFS. То есть, данная команда просто изменяет разделитель полей из запятой в точку с запятой.
Вы могли заметить, что при выполнении команды пустые строки были проигнорированы. Если Вы все-таки хотите оставить их в выводе, введите в терминале такую конструкцию команд:
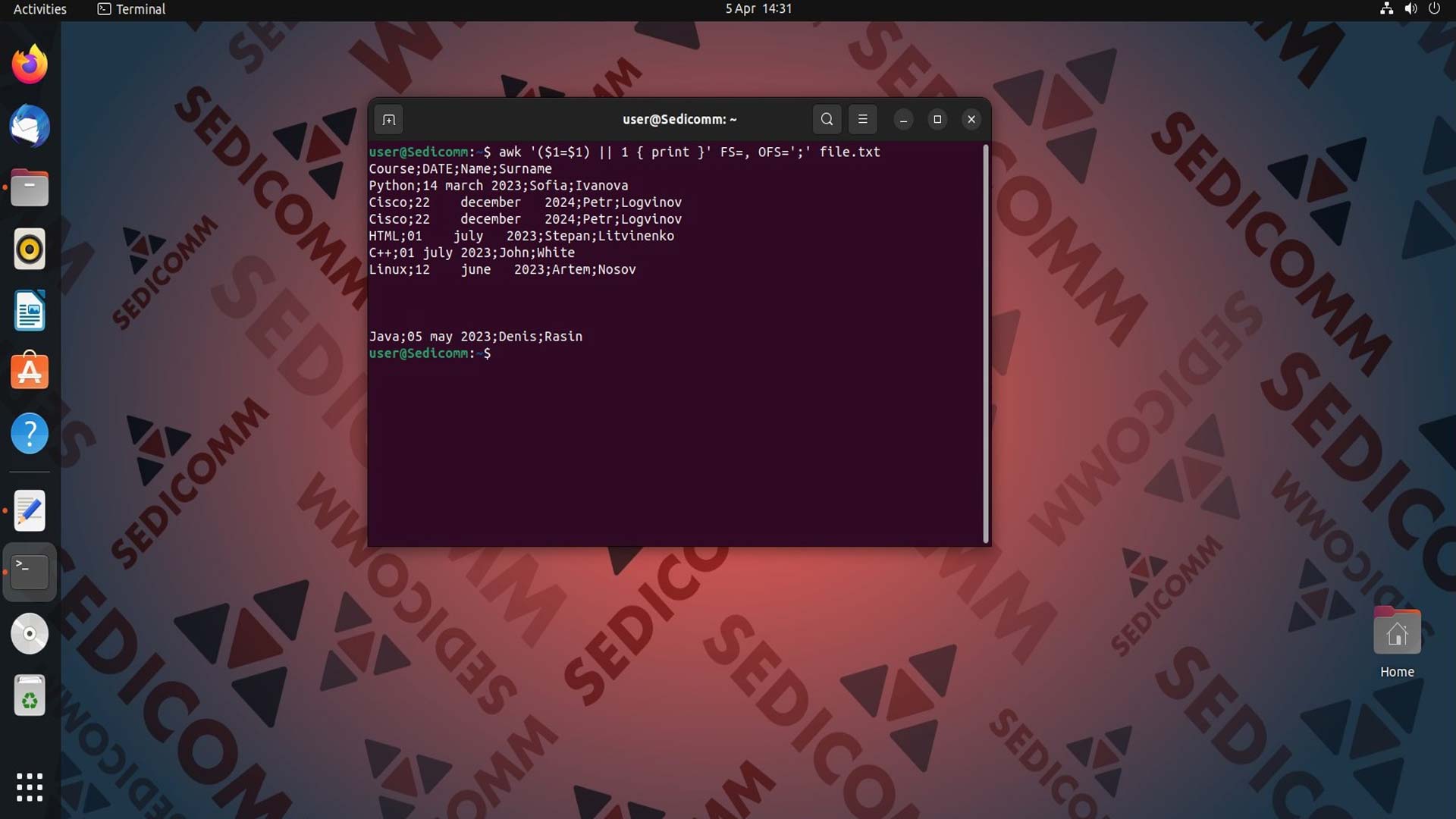
Объясним это выражение:
- Первый элемент
$1устанавливается равным себе$1=$1, что приводит к удалению ведущих и конечных пробелов. - Если первый элемент в строке теперь равен себе, то выражение
$1=$1возвращаетTrue. - Если первый элемент в строке уже был пустым или равен строке пробелов, то выражение
$1=$1возвращаетFalse. || 1используется для того, чтобы всегда вернутьTrue, если первый элемент был пустым или равен строке пробелов.
Удаление лишних пробелов
Если Вы просмотрите файл file.txt, то увидите, что в некоторых полях есть двойные или даже тройные пробелы. Чтобы отформатировать таблицу и разделить слова одинарными пробелами, введите команду в терминале:

Отображение столбцов в линию
Форматирование столбцов — одна из главных функций AWK. Благодаря ей Вы сможете изменить вид столбца. Например, вывести колонку в строку. Давайте расположим в строку первый столбец файла:

Разберем код подробнее:
FS=,— указывает AWK на использование запятой в качестве разделителя полей;ORS=' '— задает пробел в качестве разделителя строк при выводе результатов;echo— добавляет в конце символ переноса строки, чтобы разделить вывод AWK и приглашение оболочки.
Чтобы удалить из вывода пустые поля, воспользуйтесь этим регулярным выражением:
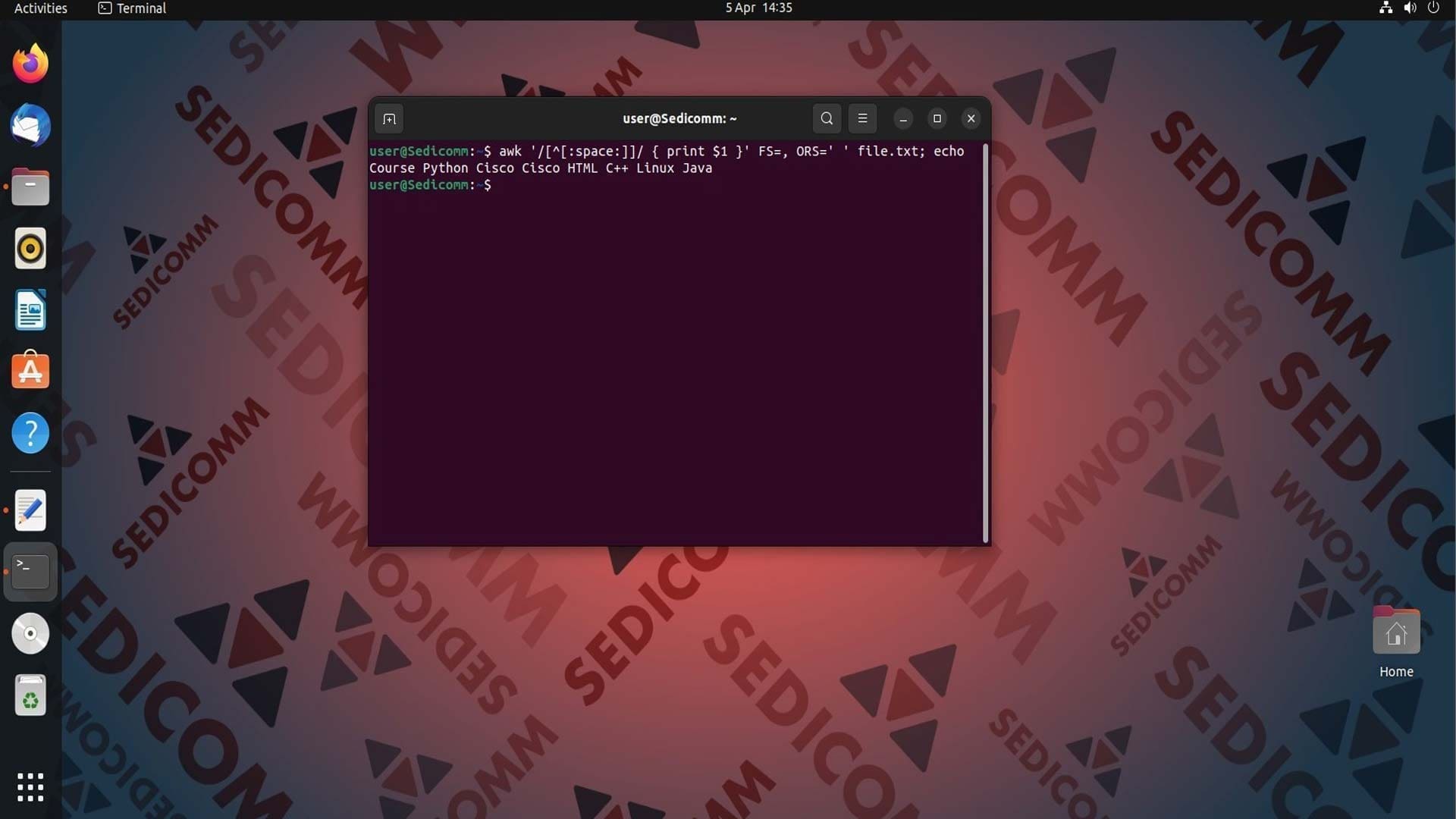
Данный код возвращает первый столбец каждой строки файла, игнорируя пустые строки и те, которые состоят только из пробельных символов. Команда /[^[:space:]]/ означает, что только строки, содержащие хотя бы один символ, который не является пробелом, будут выбраны для обработки.
Для лучшей читабельности изменим символ разделитель ORS на + и выведем таким образом на экран третий столбец:
Однако, тогда в конце строки появляется лишний плюс. Чтобы убрать его, модифицируйте предыдущую конструкцию следующим образом:.

После последнего поля разделитель + не нужен, так что используется переменная SEP, которая инициализируется пустой строкой. Эта переменная определяет, что поле последнее и не выводит символ разделитель после него.
Форматирование полей
AWK позволяет форматировать вывод полей с помощью специальных функций, таких как printf и sprintf. Первая позволяет задавать формат вывода с использованием специальных символов, таких как %s для строчного типа данных, %d для целых чисел и т. д. Вторая работает аналогичным образом, но возвращает отформатированную строку в качестве значения, которое затем можно присвоить переменной.
Для примера давайте выведем третью колонку в одну строку:

Разберем команду детальнее:
%s— означает, что нужно вывести строку как тип данных;$3— третье поле текущей строки, считая разделителем запятую (FS=,);printf("%s ", $3)— означает, что нужно вывести текст из третьего поля и добавить пробел после него;+$2— проверяет, является ли второе поле данными строчного типа;echo— добавляет символ переноса строки в конце.
Используя специальный символ \n, можно расположить полученные значения в столбик:
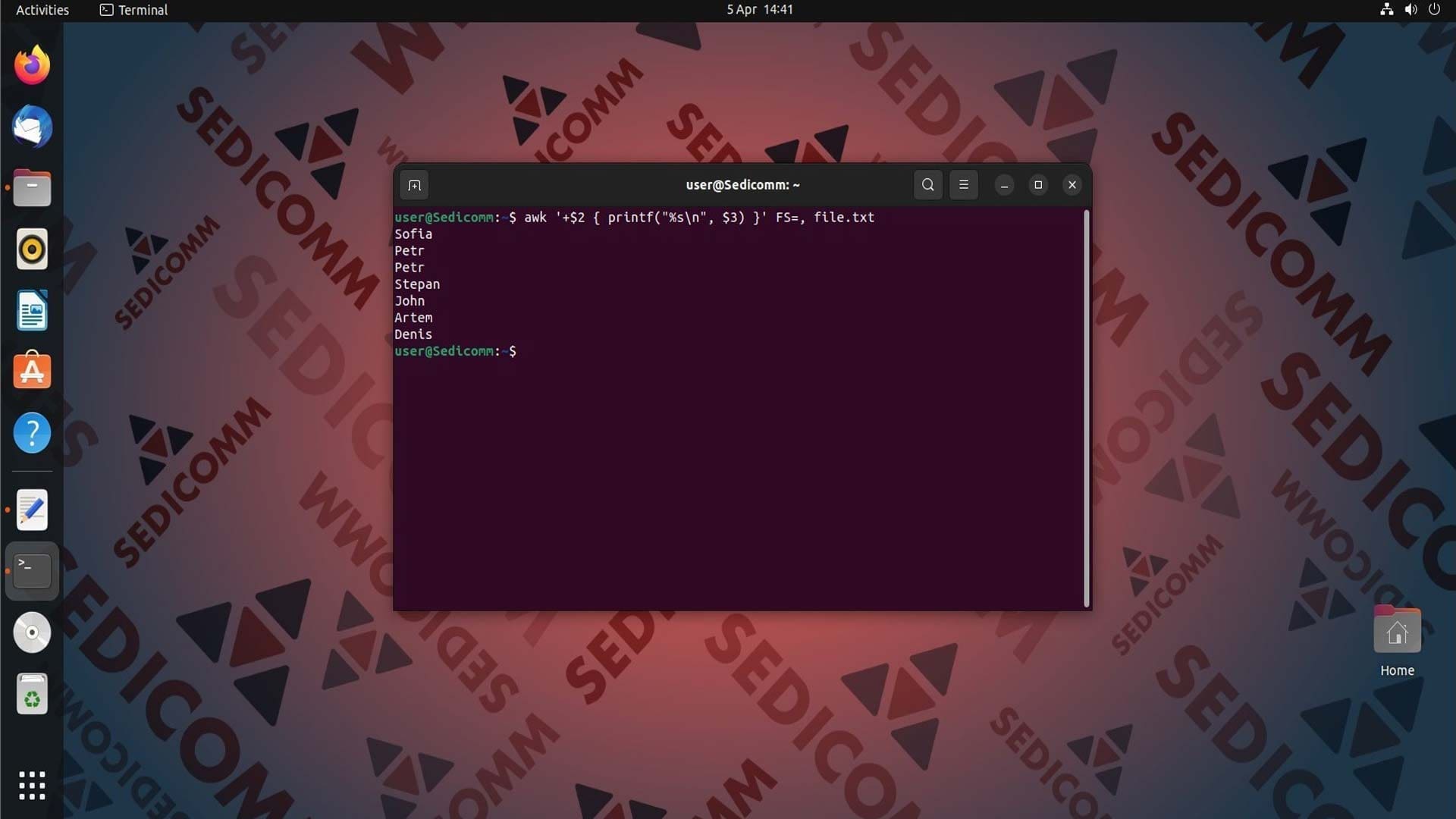
Преобразование вывода в таблицу
Для создания таблицы с помощью AWK необходимо использовать функции форматирования вывода. Одной из таких функций является printf, которая позволяет задавать формат для выводимых данных.
Например, чтобы вывести два столбца ($3 и $1) в виде таблице с вертикальной чертой (|) в качестве разделителя — будем использовать эту команду:
Здесь:
%10s— первый столбец будет шириной в 10 символов и выровнен по правому краю;%4d— второй столбец будет шириной в 4 символа и выровнен по правому краю;|— разделитель между столбцами.
Можно модифицировать вывод таблицы, так чтобы левый столбец был выровнен по левому краю, а пустые поля правого заполнялись нулями вместо пробелов:
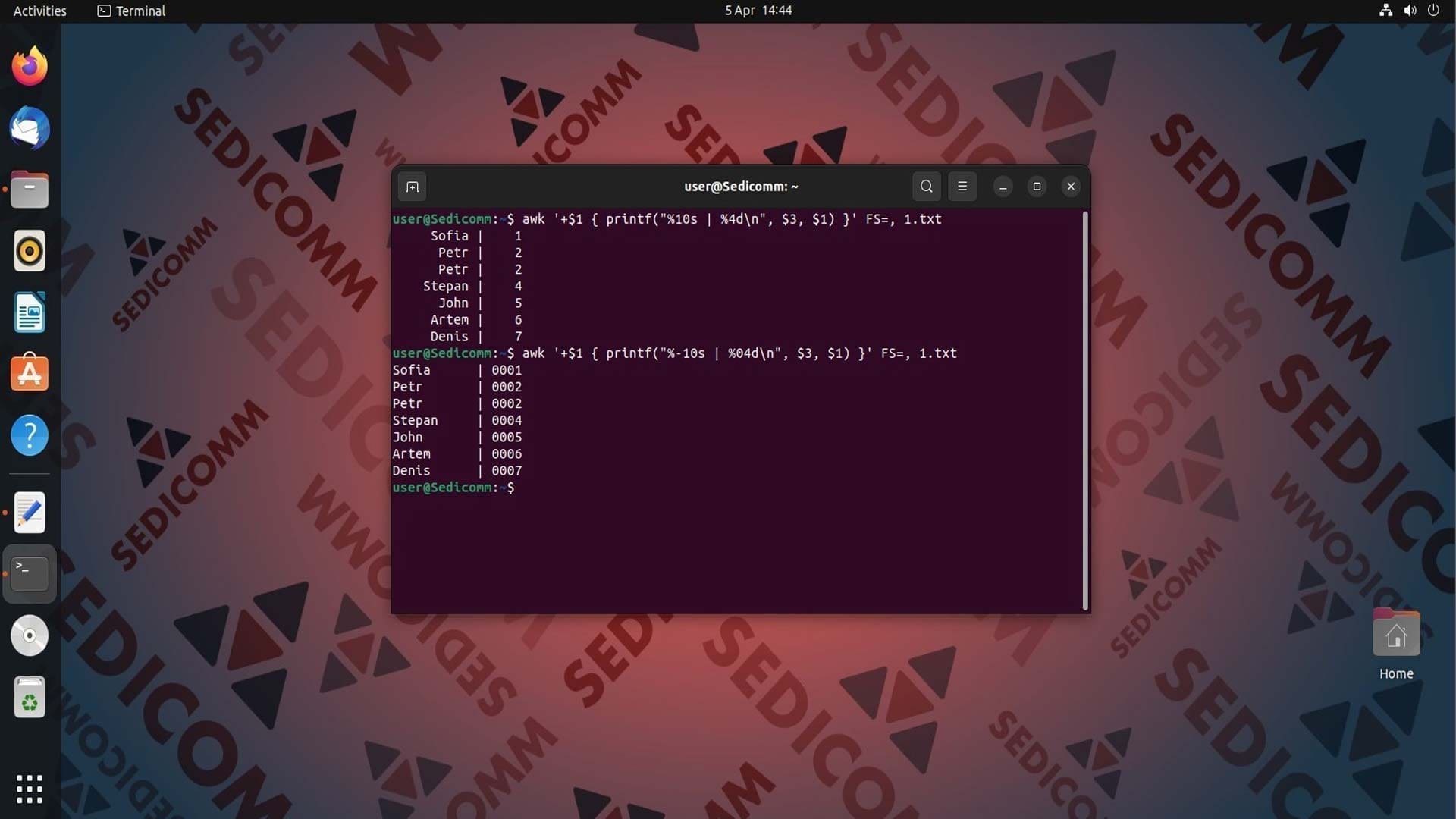
В этой конструкции:
%-10s— спецификатор формата для строчного типа данных, который указывает, что мы хотим выровнять запись по левому краю и оставить максимум 10 символов для этого поля. Знак-означает, что выравнивание будет выполнено по левому краю.%04d— спецификатор формата для целых чисел, который указывает, что мы хотим выровнять число по правому краю. Также он добавит соответствующее количество ведущих нулей, если число состоит из менее чем 4 символов.
Операции с числами с плавающей запятой
В AWK для операций с числами с плавающей запятой используется форматирование полей %f. С его помощью можно указать количество знаков после запятой и выравнивание значений. К примеру:
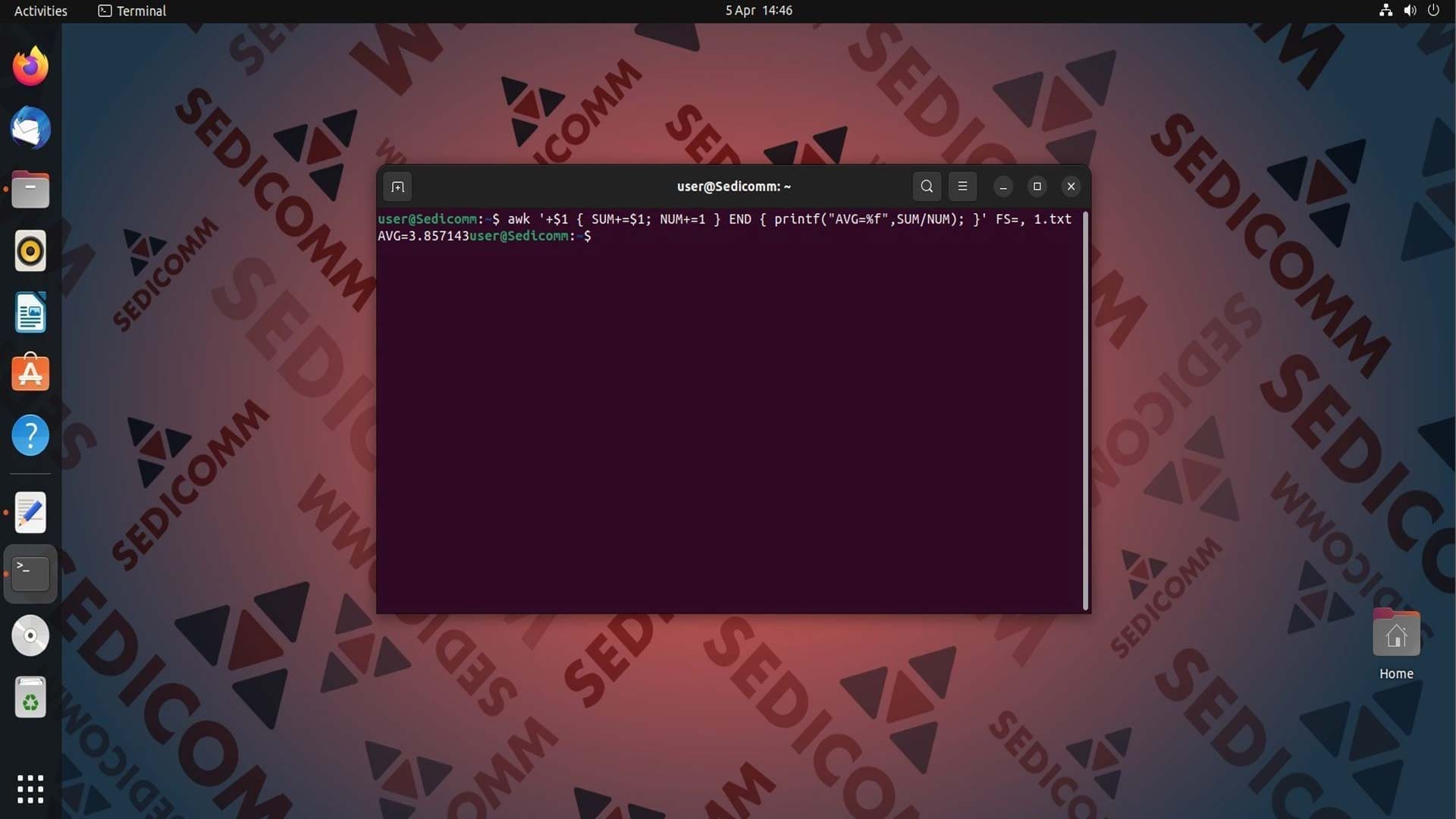
Данный код использует скриптовый язык для вычисления среднего значения с запятой в качестве разделителя:
+$1— условие, которое проверяет, не является ли нулем значение в первом столбце;{ SUM+=$1; NUM+=1 }— для каждой строки, где выполняется условие, AWK добавляет значение из первого столбца к переменнойSUMи увеличиваетNUMна 1;END { printf("AVG=%f",SUM/NUM); }'— после обработки всех строк, язык сценариев делитSUMнаNUM, и выводит результат в отформатированном виде с помощью функцииprintf.
Таким образом, данный код выводит среднее значение всех чисел в первом столбце файла в формате AVG=значение.
Использование строчных функций в AWK
Язык сценариев AWK предоставляет ряд встроенных строчных функций, которые позволяют выполнять операции с текстом. Некоторые из них:
tolower(str)— преобразование строки в нижний регистр;toupper(str)— преобразование строки в верхний регистр;length(str)— возвращение длины строки;index(str, sub_str)— возвращение позиции первого вхождения подстрокиsub_strв строкеstr;substr(str, start, length)— возвращение подстроки строкиstr, начинающуюся с позицииstartи имеющую длинуlength;
Рассмотрим несколько строчных функций.
Преобразование строки в верхний регистр
В файле file.txt все текстовые поля записаны с маленькой буквы. Допустим, нам нужно перевести все буквы нижнего регистра в верхний:

Давайте проанализируем элементы выражения { print toupper($0); }:
print— выводит результаты работы команды на экран;toupper($0)— вызывает функцию преобразования из нижнего регистра в верхний с аргументом$0.
Важно: аргумент $0 соответствует переменной, содержащей строку целиком.
В итоге текст из файла будет преобразован в верхний регистр и выведен на экран.
Изменение части строки
Функции скриптового языка позволяют изменять заданные фрагменты текста в каждом поле. Для этого нам понадобится функция substr(str, start, length). К примеру, преобразим в верхний регистр первую букву третьего поля каждой строки:

Разберем эту конструкцию:
FS=,— устанавливает запятую (,) в качестве разделителя полей входного файла;OFS=,— устанавливает запятую (,) в качестве разделителя полей при выводе данных;toupper(substr($3,1,1))— переводит первую букву третьего поля в верхний регистр;substr($3,2)— извлекает оставшуюся часть третьего поля, начиная со второго символа;$3 =— присваивает третьему полю новое значение;$3— условие, проверяющее, что третье поле не пустое (это необходимо, чтобы избежать присвоения пустых значений полям).
Разделение полей на подполя
Одно поле строки может также содержать в себе несколько других элементов (например, 14 march 2023). Следовательно, поля можно разбить на подполя. Например:
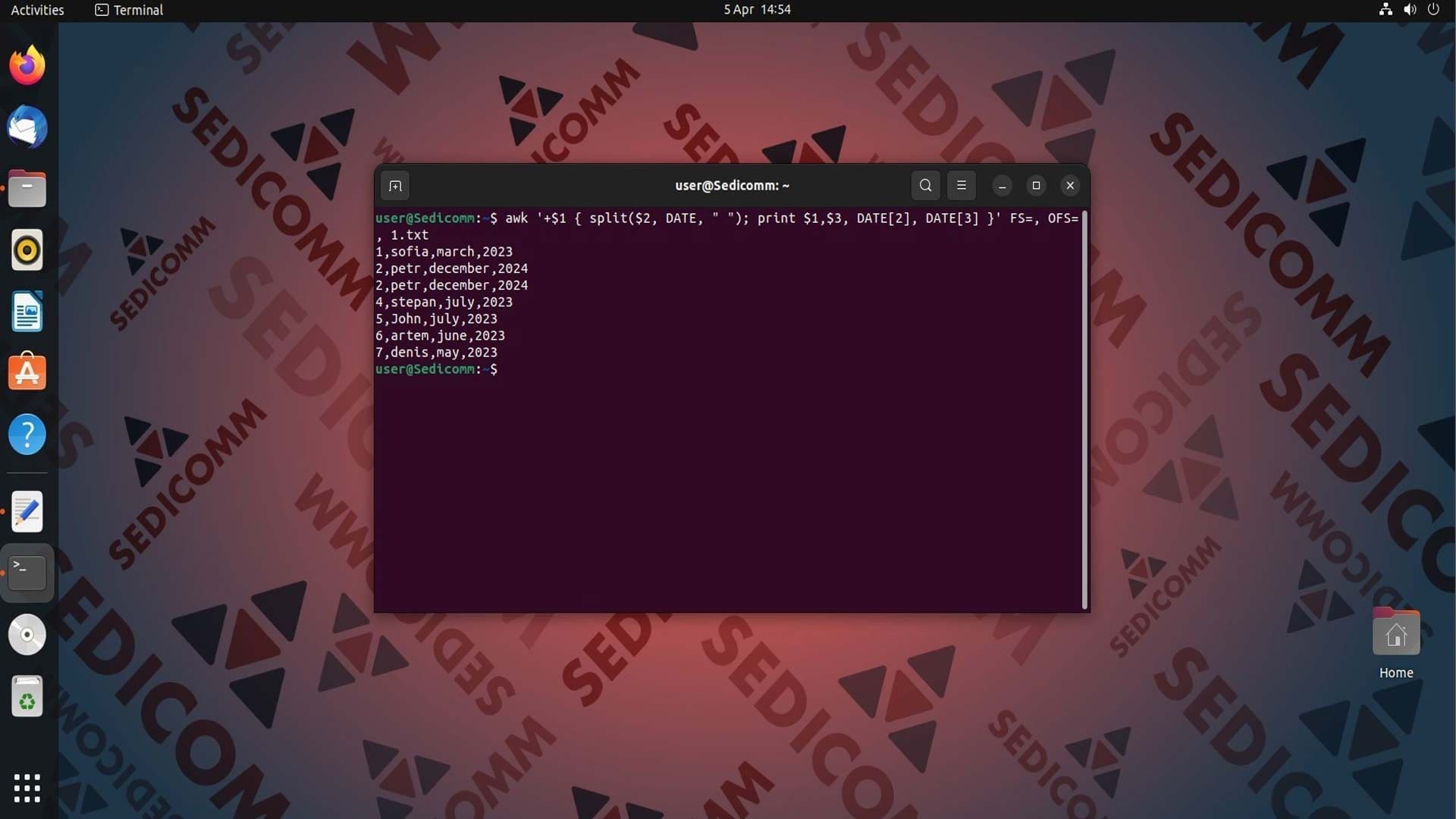
Данный код производит такие действия:
+$1— проверяет, является ли первое поле числом, и если да, то выполняет следующую часть команды.split($2, DATE, " ")— разбивает значения второго поля файла на подстроки, используя пробел в качестве разделителя. Результат разбиения будет сохранен в массивеDATE.print $1,$3, DATE[2], DATE[3]— выводит значения первого поля, третьего поля, второй и третьей подстроки из массиваDATE. Разделителем полей при выводе является запятая, что задается опциейOFS=,.
Использование внешних команд в AWK
В AWK можно вызывать внешние команды с помощью функции system(). Синтаксис вызова команды следующий:
Здесь "command arg1 arg2 argN" — это строка, содержащая вызываемую команду и ее аргументы.
Добавление даты в файл
Например, добавим в первую строку текущее время системы:

Элементы этой конструкции выполняют определенные действия:
BEGIN { printf("UPDATED: "); system("date") }— выводит в терминал сообщениеUPDATED:с помощью функцииprintf. Также отображает результат выполнения внешней командыdate, используя функциюsystem()./^UPDATED:/ { next }— проверяет, начинается ли текущая строка с сообщенияUPDATED:. Если это так, то командаnextпропускает строку и переходит к следующей.1— соответствует любой строке, которая не была обработана ранее.
Изменение внешних переменных
Допустим, у Вас в таблице есть список пользователей системы и Вы хотите сгенерировать UUID и вставить его в новый столбец:
Этот код AWK использует внешнюю команду uuid -v4, чтобы сгенерировать UUID и затем вставляет его в пятое поле каждой строки входного файла.
Давайте более подробно рассмотрим каждую часть этой команды:
CMD="uuid -v4"— создает переменнуюCMDи устанавливает ее значение как строку"uuid -v4". Эта переменная будет использоваться внутри AWK для запуска внешней команды.CMD | getline $5— выполняет внешнюю команду, указанную в переменнойCMD, и передает ее вывод в качестве ввода дляgetline.getline— сохраняет ввод в пятый столбец ($5) текущей строки.close(CMD)— закрывает поток, созданный внешней командой.print— выводит измененную строку на экран.
После выполнения скрипта каждая строка файла будет содержать уникальный UUID, сгенерированный внешней командой uuid -v4.
Вызов динамически сгенерированных команд
В AWK есть возможность динамически генерировать команды и выполнять их с помощью функции system(). Для этого необходимо создать строку, содержащую команду, и передать ее в функцию system(). Это может быть полезно, когда Вы хотите создать команду, используя значения из входного файла или переменных AWK.
Предположим, что у вас есть файл, содержащий названия файлов. Вы можете использовать AWK для создания и выполнения команды, которая выводит размер каждого файла в этом списке:
В этом коде:
cmd=— присваивает переменной строчного типа значение, содержащее команду.- AWK генерирует команду
ls -l " $1 " | awk '{print $5}'. - Затем скриптовый язык выполняет эту команду с помощью
cmd | getline size. size— это переменная AWK, которая будет содержать вывод команды.- Затем AWK закрывает команду с помощью
close(cmd)и выводит имя файла и его размер.
Это простой пример того, как можно использовать динамически сгенерированные команды в AWK. Данный метод может быть особенно полезен, когда нужно обработать каждую строку отдельно.
Выводы
В этом руководстве мы рассмотрели основные сферы применения AWK и показали, как использовать его для выполнения различных задач обработки текстовых файлов. Мы начали с описания базовых элементов языка, таких как поля и операторы. А затем перешли к более продвинутым инструментам, таким как массивы, временные переменные и внешние команды.
Мы также рассмотрели различные примеры использования скриптового языка, включая форматирование вывода, обработку чисел с плавающей запятой, работу со строками и вызов внешних команд.
Спасибо за время, уделенное прочтению статьи!
Если возникли вопросы — задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!
Чтобы знать больше и выделяться знаниями среди толпы IT-шников, записывайтесь на курсы Cisco, курсы по кибербезопасности, полный курс по кибербезопасности, курсы DevNet / DevOps (программируемые системы) от Академии Cisco, курсы Linux от Linux Professional Institute на платформе SEDICOMM University (Университет СЭДИКОММ).
Курсы Cisco, Linux, кибербезопасность, DevOps / DevNet, Python с трудоустройством!
- Поможем стать экспертом по сетевой инженерии, кибербезопасности, программируемым сетям и системам и получить международные сертификаты Cisco, Linux LPI, Python Institute.
- Предлагаем проверенную программу с лучшими учебниками от экспертов из Cisco Networking Academy, Linux Professional Institute и Python Institute, помощь сертифицированных инструкторов и личного куратора.
- Поможем с трудоустройством и стартом карьеры в сфере IT — 100% наших выпускников трудоустраиваются.
- Проведем вечерние онлайн-лекции на нашей платформе.
- Согласуем с вами удобное время для практик.
- Если хотите индивидуальный график — обсудим и реализуем.
- Личный куратор будет на связи, чтобы ответить на вопросы, проконсультировать и мотивировать придерживаться сроков сдачи экзаменов.
- Всем, кто боится потерять мотивацию и не закончить обучение, предложим общение с профессиональным коучем.
- отредактировать или создать с нуля резюме;
- подготовиться к техническим интервью;
- подготовиться к конкурсу на понравившуюся вакансию;
- устроиться на работу в Cisco по специальной программе. Наши студенты, которые уже работают там: жмите на #НашиВCisco Вконтакте, #НашиВCisco Facebook.






















